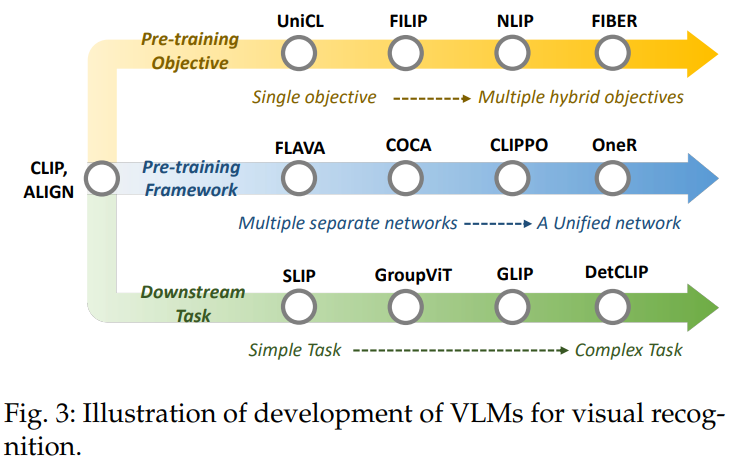
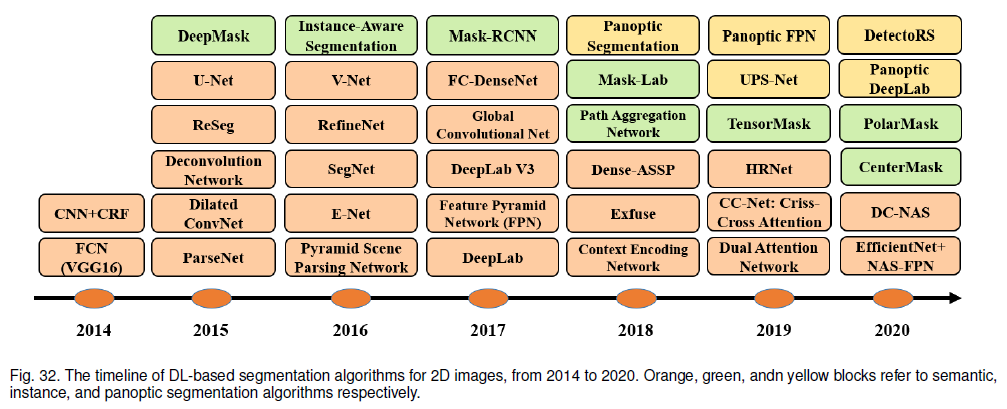
Abstract vision recognition 연구 = DNN에 있는 crowd labeled data에 의존-> 힘들고 시간 소모 많음 zero shot 예측이 가능하고 web scale image-text pair로 vision-language 상관관계를 학습하는 Vision-Language Model(VLM)을 제시 Introductionmachine learning에서 deep learning으로 변하면서 두가지 문제 발생-> 1. DNN의 느린 수렴 2. large-scale, task-specific, crowd-labeled data의 힘든 수집 pretraining, fine tuning, prediction은 visual recognition task에서 효과적이였음DNN ..