Abstract

vision recognition 연구 = DNN에 있는 crowd labeled data에 의존
-> 힘들고 시간 소모 많음
zero shot 예측이 가능하고 web scale image-text pair로 vision-language 상관관계를 학습하는 Vision-Language Model(VLM)을 제시
Introduction
machine learning에서 deep learning으로 변하면서 두가지 문제 발생
-> 1. DNN의 느린 수렴
2. large-scale, task-specific, crowd-labeled data의 힘든 수집
pretraining, fine tuning, prediction은 visual recognition task에서 효과적이였음
DNN model은 annotate되거나 unannotate된 large scale training data로 pretrain됐고, pretrain된 model은 task specific annotate된 training data로 fine tune됐다.
-> network 수렴을 가속화되고 다양한 downstreaming task에 대해 잘 학습된 model을 학습한다.
하지만 pretraining, fine tuning, prediction은 downstream task로부터 label된 training data를 가지는 task specific fine tuning의 추가 stage를 요구
-> Vision-Language Model Pretraining과 Zero shot predicition 급부상
Vision-Language Model(VLM)은 large-scale image-text pair로 pretrain했고, fine tuning없이 downstream visual recognition task를 적용한다.
VLM pretraining은 large-scale image-text pair로부터 image-text 일관성을 학습하는 vision-language objective에 의해 안내된다.
ex) CLIP
CLIP은 image-text contrastive objective를 이용하고 embedding space에서 pair된 image와 text를 가깝게 하고, 다른 것들은 멀리함으로써 학습한다.
pretrain된 VLM은 풍부한 vision-language correspondence knowledge를 가지고, image와 text의 embedding을 일치함으로써 zero shot prediction을 한다.
-> web data의 효과적인 사용할 수 있고 task specific fine tuning없이 zero shot prediction 할 수 있다.
-> CLIP: 엄청난 zero shot 성능 보임
- VLM의 두가지 연구
1. transfer learning을 가지는 VLM
ex) prompt tuning, visual adaptation 등
다양한 downstream task에 대한 pretrain된 VLM의 효과적인 적응에 대해 같은 target을 공유함
2. knowledge distillation을 가지는 VLM
object detection, semantic segmentation 등에서 더 나은 성능 목표로 하는 VLM에서 downstream task으로 지식을 증류하는 방법을 찾는다.
Background
Training Paradigms for Visual Recognition
- Traditional Machine Learning and Prediction
deep learning 전에는 hand-crafted feature로 feature engineering을 했고 경량화 모델을 학습했다.
-> 특정 visual recognition task에 대해 효과적인 feature를 구할려면 domain 전문가를 요구한다.
- Deep learning from scratch and prediction
deep learning의 발전으로 복잡한 feature engineering를 안해도 되었고, neural network의 구조 engineering에 집중했다.
ex) Resnet
- deep learning의 두가지 문제
1. 처음부터 deep learning을 학습하면 수렴이 느림
2. large-scale, task-specific, crowd-labeled data를 모으기 어려움
- Supervised Pre-training, Fine-tuning and Prediction

labeled large-scale dataset으로부터 학습된 feature가 downstream task에 옮겨지는 발견으로, deep learning은 supervised pre-training, fine-tuning, prediction으로 대체되었다.
-> pre-train된 DNN은 visual 지식을 학습하기 때문에 network 수렴이 빨라지고 제한된 task-specific data에서 좋은 성능을
보이도록 도와준다.
- Unsupervised Pre-training, Fine-tuning & Prediction

Supervised Pre-training, Fine-tuning, Prediction으로 visual recognition task에 sota 성능을 보였다.
하지만 pre-training에는 large-scale labeled data가 필요하다.
-> Unsupervised Pre-training, Fine-tuning, Prediction 제시(Self-supervised learning)
다양한 self supervised training objective는 training sample을 대조함으로써 discriminative feature를 학습하는 contrastive learning, cross-patch 관계를 modeling하는 masked image modeling을 제안한다.
self supervised pre-trained model은 label된 task-specific training data로 down-stream task에 fine tuning한다.
-> pre-training에서 labeled data가 필요없기 때문에 더 많은 training data를 이용할 수 있어서 성능이 좋아짐
- VLM pre-training and Zero-shot Prediction

supervised나 unsupervised pre-training을 가지는 Pre-training, Fine-tuning은 network 수렴이 향상됨에도 불구하고, labeled task data를 가지는 fine-tuning stage는 필요하다.
large-scale image-text pair를 가지는 VLM은 풍부한 vision-language 지식을 포착하는 vision-language objective로서 pre-train되고 주어진 image와 text의 embedding을 matching함으로써 downstream visual recognition task에서 zero-shot prediction을 수행한다.
VLM은 task-specific fine-tuning없이 large-scale web data와 zero-shot prediciton의 효율적인 사용을 하게한다.
- VLM을 향상시키는 3가지 관점
1. large-scale image-text data 모으기
2. big data 수용가능한 model design
3. 새로운 pre-training objective design
Development of VLMs for Visual Recognition
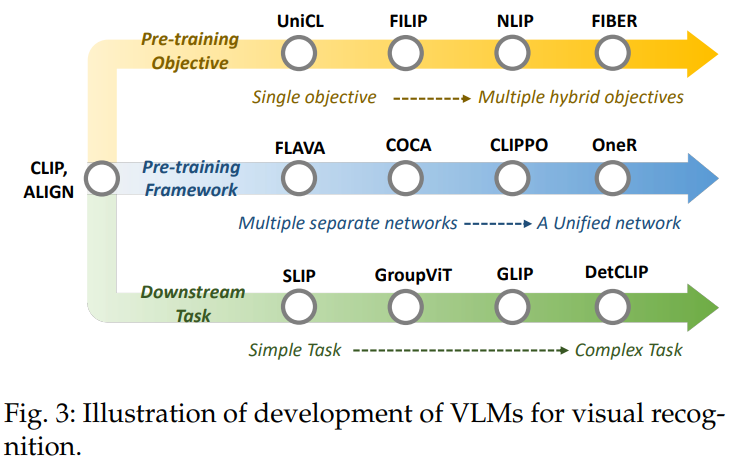

VLM 연구는 CLIP의 발전으로 엄청나게 진보했다.
- VLM의 3가지 관점
1. Pre-training objective
single objective -> multiple hybrid objective
초기 VLM: single pre-training objective를 사용
최근 VLM: multiple objective를 소개
2. Pre-training framework
multiple separate network -> unified network
초기 VLM: two-tower pre-training framework 이용
최근 VLM: unified network로 image와 text를 encode하는 one-tower pre-training framework
-> GPU memory 덜 사용하지만 data 양상을 지나 더 효율적인 communication을 한다.
3. Down-stream task
simple task -> complex task
초기 VLM: image-level visual recognition task에 집중
최근 VLM: 복잡하고 localization을 요구하는 prediction task에 대해 하는 것이 일반적이다.
VLM Foundations
VLM pre-training은 image-text 상관관계를 학습하고 visual recognition task에서 효과적인 zero-shot prediction을 초점을 두기 위해 VLM을 pre-train하는 것에 목표를 둔다.
image-text pair를 고려해서 image와 text feature를 추출하기 위해 text encoder와 image encoder를 이용한다.
pre-training objective로 vision-language 상관관계를 학습한다.
-> 주어진 image와 text의 embedding을 match함으로써 zero-shot 방식으로 unseen data를 처리한다.
Network Architectures
VLM pre-training은 pre-training dataset 안에 있는 N개의 image-text pair로부터 image와 text feature를 추출하는 dnn으로 수행한다.
- Architectures for Learning Image Features
- CNN-based Architectures
다른 convnet은 image feature를 학습하기 위해 design됨
ex) VGG, Resnet, Efficientnet
Resnet: gradient vanishing과 explosion을 완화시키기 위해 convolution block 사이에 skip connection을 사용해서 deep neural network도 가능하다.
ResNet-D: antialiase된 rect-2 blur pooling을 사용하고 multi-head attention에 있는 attention pooling과 global average pooling을 대체한다.
- Transformer-based Architectures
ViT는 multi-head self-attention layer와 feed-forward network를 구성하는 transformer block의 stack을 사용한다.
input image는 먼저 고정된 size patch를 나누고 linear projection과 position embedding 후에 transformer encoder에 넣는다.
- Architectures for Learning Language Features
일반적으로 transformer는 encoder-decoder 구조를 가지고, multi-head self-attention layer와 MLP를 가지는 block이 6개있다.
decoder는 multi-head attention layer, masked multi-head layer, MLP를 가지는 block이 6개있다.
VLM 연구는 GPT2로서 약간의 수정이 있는 transformer를 사용하고 GPT2 weight와 같은 초기값없이 처음부터 학습한다.
VLM Pre-training Objectives
- Contrastive Objectives
: feature space에서 가까운 paired sample을 당기고 멀리 있는 나머지는 밀어버림으로써 discriminative representation을 배우는 VLM을 학습한다.
- Image Contrastive Learning
: embedding space에서 positive key(data augmentation)외 가까워지고 negative key(다른 image)와 멀어지기 위해 query image에 집중함으로써 discriminative image feature를 학습한다.

- Image-Text Contrastive Learning
: paired image와 text의 embedding이 가까우면 끌어당기고 다른 것들은 밀어버림으로써 학습

대칭적인 image-text infoNce loss를 최소화시키는 것이 목표이다.
- Image-Text-Label Contrastive Learning
: image-text contrastive learning에 supervised contrastive learning을 도입한다.

- Generative Objectives
- Masked Image Modeling
: masking과 reconstructing image로 cross-patch 상관관계를 학습
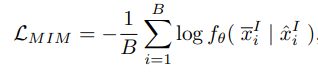
랜덤하게 input image의 patch를 mask하고 mask되지않은 patch로 mask된 patch를 reconstruct하기 위해 encoder로 학습한다.
- Masked Language Modeling
: NLP에 있는 pretraining objective를 사용

input text token의 일부분을 random하게 mask하고 unmask된 token으로 reconstruct한다.
- Masked Cross-Modal Modeling
: masked image model과 masked language model을 통합함

image-text pair를 고려해서, image patch의 subset과 text token의 subset을 랜덤하게 mask하고 unmasked image patch와 unmasked text token을 조건으로 reconstruct하기 위해 학습한다.
- Image-to-Text Generation
: paired image에 기반해서 text를 예측한다.
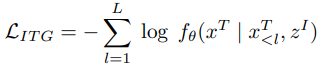
- Alignment Objectives
: embedding space에서 global image-text matching or local region-word matching를 통해 image-text pair를 할당
- Image-Text Matching
: image와 text 간 global 상관관계를 modeling한다.

- Region-Word Matching
: image-text pair에 있는 local cross-modal 상관관계를 model한다.

VLM Pre-training Frameworks

- two-tower framework
: input image와 text가 두 separate encoder로 encode됨
- two-leg framework
: image와 text modality 간 feature interaction을 하게하는 추가적인 multi-modal fusion layer를 도입함
- one-tower framework
: single encoder에 있는 vision과 language learning을 통하기 위해 시도함
Evaluation Setups and Downstream Tasks
- Zero-shot Prediction
- Image Classification
: image와 text의 embedding을 비교함으로써 zero-shot image classification함
"prompt engineering": task에 관련된 prompt를 생성하기 위해 사용
ex) a photo of a [label]
- Semantic Segmentation
: image에 있는 각 pixel에 category label를 할당함
segmentation task를 위해, 주어진 image pixel과 text의 embedding을 비교함
- Object Detection
: image에 있는 object를 분류하고 localize함
보조 dataset으로부터 학습된 object locate하는 능력으로 pre-trained VLM은 주어진 object proposal과 text의 embedding을 비교함으로써 object detection task에 대해 zero-shot prediction을 달성함
- Image-Text Retrieval
: 두 task를 구성하는 다른 modality로부터 단서가 주어지면 하나의 modality로 요구되는 sample을 검색함
- Linear Probing
Linear Probing은 pretrain된 VLM을 동결하고 VLM을 분류하기 위해 linear classifier을 학습한다.
Datasets
Datasets for pre-training VLMs


많은 large-scale image-text dataset은 인터넷으로 모아졌다.
crowd-labeled dataset과 비교하면 image-text dataset이 훨씬 더 크고, 모으기 더 쉽다.
Vision-Language Model Pre-Training

VLM Pre-Training with Contrastive Objectives
- Image Contrastive Learning
: image modality에 있는 discriminative feature를 학습하는 것이 목표
ex) SLIP
: 기존 infoNCE loss 사용
- Image-Text Contrastive Learning
: image-text pair을 대조함으로써 vision-language 상관관계를 학습하는 것이 목표

paired image와 text의 embedding이 가까우면 = pull
멀리 있는 나머지 embedding = push
ex)
1. CLIP
: image와 text embedding 간 dot-product에 의해 image-text similarity를 측정하는 대칭적인 image-text infoNCE loss 사용
2. ALIGN
: large-scale으로 VLM pre-training
-> noise-robust contrastive learning으로 noise가 있는 image-text pair를 만듦
3. DeCLIP
: 비슷한 pair로부터 정보를 활용하기 위해 nearest-neighbor supervision을 도입
4. OTTER
: training data를 줄이기 위해 pseudo-pair image와 text를 최적의 이동을 이용
5. ZeroVL
: coin flipping mixup으로 bias가 없는 data sampling과 augmentation을 통해 제한된 data resource를 사용
- 다양한 semantic level으로 image-text contrastive learning을 수행함
ex)
1. FILIP
: fine-grain된 vision-language에 일치하는 지식을 학습하는 contrastive learning에 region-word alignment를 도입
2. PyramidCLIP
: 많은 semantic level을 구성하고 VLM pre-training에 대한 cross level, peer level contrastive learning 둘 다 수행한다.
- image-text pair를 augment함으로써 향상됨
ex)
1. LA-CLIP, ALIP
: 주어진 image에 대한 caption을 증가시키기 위해 큰 language model 사용
2. RA-CLIP
: image-text pair augmentation에 대한 관련된 image-text pair를 얻음
- Image-Text-Label Contrastive Learning

공유된 space에 있는 image, text, classification label을 encode하는 image-text contrast에 있는 image classification label을 도입
image label으로 supervised pre-training한 것과 image-text pair로 unsupervised VLM pretraining 둘 다 사용한다.
ex) UniCL
: pre-training은 discriminative와 task-specific feature를 동시에 학습함
- Discussion
Contrastive objective는 negative pair에 대조해서 비슷한 embedding을 가지는 positive pair를 수행한다.
discriminative vision과 language feature를 학습하는 VLM을 권장함
-> 하지만, contrastive objective는 두가지 한계가 있음
- contrastive objective 두가지 한계
1. Joint optimizing positive와 negative pair는 복잡하고 어려움
2. feature discriminability를 다루기 위해 temperature hyper parameter를 포함함
VLM Pre-training with Generative Objectives
Generative VLM pre-training은 masked image modeling, masked language modeling, masked cross-modal modeling, image-to-text generation을 통해 image or text를 생성하기 위해 학습함으로써 semantic knowledge를 학습한다.
- Masked image Modeling
: image를 masking과 reconstruct함으로써 image context 정보를 학습하기 위해 지도된다.

Masked image Modeling에서 image에 있는 patch는 mask됐고 encoder는 unmask된 patch에서 patch를 reconstruct하기 위해 학습됐다.
ex)
1. FLAVA
: BeiT처럼 직사각형 block masking을 사용
2. KELIP, SegCLIP
: patch의 큰 부분을 mask out 하기 위해 MAE를 사용한다.
- Masked Language Modeling
: masked token을 예측하기 위해, network를 학습하고 각 input text에 있는 token의 부분을 masking함

ex)
1. FLAVA
: 15% text token을 mask out하고 modeling cross-word 상관관계에 대한 남은 token으로부터 token을 reconstruct한다.
2. FIBER
- Masked Cross-Modal Modeling
: image patch와 text token 둘 다 같이 mask를 하고 reconstruct한다.
unmask된 image patch와 text token의 embedding에 기반된 image patch와 text token을 reconstruct하기 위해, VLM을 학습하고 image patch와 text token의 percentage만큼을 masking한다.
ex) FLAVA
- Image-to-Text Generation
: tokenize된 text를 예측하기 위해 VLM을 학습함으로써 fine-grain된 vision-language 상관관계를 capture하는 주어진 image에 대한 text를 만드는 것이 목표

중간 embedding에 있는 input image를 encode하고 text에 있는 embedding을 decode함
ex) COCA, NLIP, PaLI
VLM Pre-training with Alignment Objectives
Alignment objective: 주어진 text가 주어진 image와 올바르게 묘사됐는지 아닌지 예측하기 위해 학습함으로써 paired image와 text를 할당하는 VLM을 한다.
VLM pre-training으로 global image-text matching과 local region-word matching으로 category된다.
- Image-Text Matching
: paired image와 text를 할당함으로써 global image-text 상관관계를 modeling한다.
ex) FLAVA, FIBER
- Region-Word Matching
: object detection과 semantic segmentation에서 zero-shot dense prediction에 이점을 주는 paired image region과 word token을 할당함으로써 local fine-grained vision-language 상관관계를 modeling한다.

ex) GLIP, FIBER, DetCLIP
VLM Transfer Learning
Motivation of Transfer learning
pre-train된 VLM은 강한 일반화 성능을 가짐에도 불구하고, 다양한 downstream task에 적용되는 동안 두 type의 격차에 직면한다.
- 두 type의 격차
1. image와 text 분포에서 격차
-> downstream dataset은 task-specific image style과 text format을 가짐
2. training objective에서 격차
-> VLM은 task-agnostic objective로 학습되고, 일반적인 concept를 학습한다.
Common Setup of Transfer Learning
supervised transfer, few-shot supervised transfer, unsupervised transfer으로 domain gap을 완화한다.
- 3가지 transfer setup
1. supervised transfer
: pre-train된 VLM을 fine-tuning하기 위해 모두 label된 downstream data를 사용
2. few-shot supervised transfer
: 작은 양의 label된 downstream sample을 사용함
3. unsupervised transfer
: fine-tuning VLM에 대한 unlabeled downstream data를 사용
Common Transfer Learning Methods

prompt tuning 방법, feature adapter 방법, 다른 방법을 포함하는 3가지 category에 있는 존재하는 VLM transfer 방법으로 group한다.
- Transfer via Prompt Tuning
많은 VLM prompt learning 방법은 전체 VLM을 fine-tuning없이 최적의 prompt를 찾음으로써 downstream task을 맞추는 VLM을 제시한다.
- 3가지 방법
1. text prompt tuning
2. visual prompt tuning
3. text-visual prompt tuning
- Transfer with Text Prompt Tuning

각 task에 대한 text prompt를 design하는 prompt engineering과 달리, text prompt tuning은 각 class에 대한 label된 downstream sample을 가지는 학습가능한 text prompt를 사용한다.
ex)
1. CoOp
: 학습가능한 word vector로 single class 이름에 대한 context word를 학습하기 위해 context 최적화를 함
2. CoCoOp
: 각 image에 대한 특정 prompt를 만드는 조건부 context 최적화를 사용
3. SubPT
: 학습된 prompt의 일반화를 향상시키기 위해 subspace prompt tuning을 design함
4. LASP
: hand-engineer된 prompt으로 학습가능한 prompt를 정규화함
5. VPT
: instance-specific 분포를 가지는 text prompt를 modeling한다.
6. KgCoOp
: textual 지식을 잊어버리는 것을 완화함으로써 unseen class의 일반화를 향상시킴
7. SoftCPT
: multiple few-shot task에서 VLM을 fine tuning한다.
8. PLOT
: multiple prompt를 학습하기 위해 최적의 방법을 이용한다.
9. DualCoOp
: multi-label classification에 대한 positive와 negative prompt 둘다 사용함
10. Tal-DP
: coarse-grained와 fine-grained embedding 둘 다 capture하는 것에 대해 double-grained prompt tuning을 도입함
11. DenseCLIP
: dense prediction을 위해 text prompt를 맞추기 위해 visual feature를 이용하는 language에 기반된 fine-tuning을 이용함
12. ProTeCt
: hierarchical classification task에 대한 model prediction의 일관성을 향상시킨다.
더 나은 annotation 효율성과 확장성을 위해 unsupervised prompt tuning을 학습한다.
ex)
1.UPL
: 선택된 pseudo-labeled sample에서 self training을 가지는 학습가능한 prompt를 최적화한다.
2. TPT
: single downstream sample로부터 adaptive prompt를 학습하기 위해 test time prompt tuning을 이용함
- Transfer with Visual Prompt Tuning
visual prompt tuning은 image encoder의 input을 조절함으로써 VLM을 transfer한다.
ex) VP
: $x^{I}+v$로 input image인 $x^I$를 수정하기 위해 학습가능한 image perturbation $v$를 사용함
Re-Prompt는 downstream task로부터 지식을 영향력을 주는 visual prompt tuning에 retrieval mechanism을 통합한다.
- Transfer with Text-Visual Prompt Tuning
: 동시에 text와 image input을 조절함
ex)
1. UPT
: text와 image prompt를 최적화하기 위해 prompt tuning을 통합함
2. MVLPT
: text와 image prompt tuning에 cross-task 지식을 포함하기 위해 multi-task vision-language prompt tuning을 사용함
3. MAPLE
: 일치하는 language prompt를 가지는 visual prompt를 할당하고, text prompt와 image prompt 간 상호적인 활동을 함으로써 multi-modal prompt tuning을 한다.
4. CAVPT
: visual concept에 더 집중하기 위해 visual prompt를 하기 위해 class aware visual prompt와 text prompt 간 cross attention을 도입
- Discussion
prompt tuning은 적은 학습가능한 text/image prompt으로 input text/image를 수정함으로써 효율적인 parameter로 VLM을 transfer한다
-> 기존 VLM의 manifold에 의해 적은 융통성으로 한계가 있다
- Transfer via Feature Adaptation

Feature adaptation은 추가적인 light-weight feature adapter로 image or text feature를 사용하기 위해 VLM을 fine-tuning한다.
ex)
1. Clip-Adapter
: CLIP의 language와 image encoder를 하고 나서 학습가능한 linear layer를 추가하고 CLIP architecture과 동결된 parameter를 유지해서 최적화한다.
2. Tip-Adaptor
: adaptor weight로서 few shot label된 image의 embedding을 이용하는 training이 없는 adapter에 제시함
3. SVL-Adaptor
: input image에서 self-supervised learning에 대한 추가적인 encoder를 이용하는 self-supervised adapter를 design함
- discussion
Feature adaptation은 추가적인 light-weight feature adapter로 image와 text feature를 수정함으로써 VLM을 사용한다.
첨가 방식으로 다른 downstream task에 대해 잘 맞도록해서 다르고 복잡한 downstream task에 VLM을 적응하는 장점이 있지만 network architecture를 수정해야하고 지식재산으로 문제가 되는 것들은 다루기 어렵다.
- Other Transfer Methods
1. Wise-FT
: downstream task로부터 새로운 정보를 학습하기 위해 fine tuning VLM과 기존 VLM의 weight를 결합함
2. MaskCLIP
: CLIP image encoder의 architecture를 수정함으로써 dense image feature를 추출함
3. VT-CLIP
: downstream image로 의미론적으로 일치하는 text feature로 visual에 기반된 attentation을 도입함
4. CALIP
: visual과 text feature 간 효과적인 상호작용과 의사소통을 위해 parameter 없는 attention을 도입함
5. TaskRes
: pre-train된 VLM에서 오래된 지식을 이용하기 위해 text 기반된 classifier를 조절함
6. CuPL, VCD
: large language model을 이용함
VLM Knowledge Distillation
Motivation of Distilling Knowledge from VLMs
transfer에서 온전한 VLM architecture을 가지는 VLM transfer과 다르게, VLM knowledge distillation은 VLM architecture의 제한없이 일반적이고 robust한 VLM knowledge에서 task-specific model로 distill되었다.
Common Knowledge Distillation Methods

- Knowledge Distillation for Object Detection
Open-vocabulary object detection은 임의의 text으로 묘사된 object를 detect하는 것이 목표이다.
CLIP과 같은 VLM은 넓은 vocabulary를 다루는 billion-scale image-text pair로 학습하는 것처럼 detector vocabulary를 확장하기 위해 VLM knowledge를 distill하는 것을 연구한다.
ex)
1. ViLD
: embedding space가 CLIP image decoder의 embedding space로 일치하게 되도록 VLM 지식에서 two-stage detector로 distill함
2. Hi-erKD
: hierarchical global-local knowledge distillation을 이용함
3. RKD
: region-based knowledge를 이용함
4. ZSD-YOLO
: CLIP을 이용하기 위해 self-labeling data augmentation을 도입함
5. OADP
: contextual knowledge를 transfer하는 동안 proposal feature를 보존함
6. BARON
: 개인적인 region 대신에 a bag of region을 distill하기 위해 neighborhood sampling을 사용함
7. RO-ViT
: open-vocabulary detection에 대한 VLM에 대한 region 정보를 distill한다.
prompt learning을 통해 VLM distillation을 연구함
ex)
1. DetPro
: open-vocabulary object detection을 위해 연속적인 prompt representation을 학습하는 것에 대한 detection prompt technique을 도입함
2. PromptDet
: regional image embedding으로 word embedding을 할당하기 위해 regional prompt learning을 도입함
추가적으로, pretrain된 pseudo label을 가지는 VLM을 연구한다.
ex)
1. PB-OVD
: pretrain된 pseudo bounding box를 가지는 VLM으로 object detector를 학습함
2. XPM
: 생성된 pseudo mask를 가지는 VLM을 이용하는 robust한 cross-modal pseudo-labeling 전략을 도입함
3. $P^{3}OVD$
: fine-grain된 prompt tuning으로 생성된 pseudo label을 가지는 VLM을 정의하는 prompt 중심의 self-training을 이용함
- Knowledge Distillation for Semantic Segmentation
open-vocabulary semantic seg-mentation에 대한 knowledge distillation은 segmentation model의 vocabulary를 확장하기 위해 VLM에 영향력을 주고, 임의의 text에 묘사되는 pixel을 segment하는 것이 목표이다.
ex)
1. CLIPSeg
: semantic segmentation에 대한 CLIP을 확장하기 위해 경량화 transformer decoder를 도입함
2. LSeg
: segmentation model로 encode되는 pixel-wise image embedding과 CLIP text embedding간 상관관계를 최대화함
3.Zeg-CLIP
: semantic mask를 생성하기 위해, CLIP을 사용하고 base class에서 overfitting을 완화하는 relationship descriptor를 도입함
4. MaskCLIP+, SSIW
: predict된 pixel-level pseudo label로 지식을 distill함
5. FreeSeg
: mask proposal을 만들고, zero shot classification을 수행함
- Knowledge distillation for wealy-supervised semantic segmentation
: weak supervision과 VLM 둘 다 영향을 주는 것이 목표이다.
ex)
1. CLIP-ES
: category confusion 문제를 완화하는 것을 위해 class aware attention에 기반된 affinity module과 softmax function을 design함으로써 class activation map을 재정하는 CLIP을 사용함
2. CLIMS
: 높은 품질의 class activation map을 생성하기 위해, CLIP 지식을 사용한다.
Performance comparison
Performance of VLM Pre-training



Performance of VLM Transfer Learning

Performance of VLM Knowledge Distillation


Conclusion
visual recognition에 대한 Vision-language model은 web data을 사용하고 task-specific fine tuning없이 zero shot prediction을 한다.
-> recognition task에서 높은 성능을 보였음
'survey' 카테고리의 다른 글
| A Review of Deep Learning-Based Semantic Segmentation for Point Cloud (0) | 2024.07.02 |
|---|---|
| Image Segmentation Using Deep Learning: A Survey (0) | 2024.06.24 |
| A Survey of Deep Learning Techniques for Autonomous Driving (0) | 2024.04.24 |
| A survey: object detection methodsfrom CNN to transformer (0) | 2024.03.28 |