Abstract
3D scene을 이해하는 것으로 주요 단계로서 point cloud의 semantic segmentation은 주목을 받고 있다.
간접 세분화에서 직접 세분화까지 다양한 측면을 다루는 survey를 제공한다.
point 순서를 포함하는 다른 관점, multi scale, feature fusion, graph convolutional neural network(GCNN)의 fusion으로부터 직접적인 segmentation 방법뿐만 아니라 multi view, voxel grid에 기반된 간접적인 segmentation의 방법을 review한다.
point cloud segmentation에 대한 일반적인 dataset은 연구자가 task에 대해 가장 적합한 것을 고르게 도와준다.
Introduction
semantic category를 가지는 여러 region에 scene에 있는 모든 pixel이나 point를 분류하는 것이 목표였다.
현재 semantic segmentation은 3차원 scene understanding의 기본이고 geographic 정보를 mapping하는 것, navigation, positioning, computer vision, pattern recognition 등의 분야에 충족시키는 중이다.
2차원 image에 기반된 semantic segmentation은 최근에 많은 진전을 보였지만 occlusion과 다른 측면으로 2차원 data 한계때문에 불만족스러웠다.
그래서 3D voxel grid, 3D point cloud와 같은 3차원 data로 관심을 돌렸다.
point cloud data를 모으는데 사용되는 non contact 기술이 신속성, 침투성, 실시간성, 동적성, 고밀도, 고효율의 우수성을 가지고 있었다.
게다가 illumination와 자세의 문제도 발생하지 않았음에도 불구하고 복잡한 scene에서 풍부한 공간적인 정보를 제공한다.
- Challenge of point cloud semantic segmentation
point의 series로 구성되어 있는 point cloud는 중요한 geometric data representation structure로 point set이다.
공간의 특성, 무작위성, 구조화되어 있지 않은 것이 어려움을 준다.
deep learning이 2차원 image의 처리에 널리 사용됨에도 불구하고 불규칙하고 무질서한 3D point cloud에는 convolution 연산이 어려웠다.
point cloud에 적합한 cnn을 만들기 위해서, 규칙적인 구조(multi-view, voxel grid, point cloud)로 data를 바꿨다.
- Related previous work

Lidar, microsoft Kinect와 같은 3D data capturing device의 발전은 더 간편하게 되었다.
- 전통적인 point cloud segmentation 알고리즘
1. attribute clustering에 기반된 방법
2. model fitting에 기반된 방법
3. region growth에 기반된 방법
4. graph cut 기반된 방법
5. edge에 기반된 방법
그러나 이 방법은 geometric 억제로부터 수작업으로 되는 feature를 채택하고 추정된 이전의 지식으로 제한되었다.
parameter 조절은 어려웠고, segmentation 결과는 통제불가능했다.
원래, 연구자들은 machine learning에 기반된 방법을 채택했다.
ex) Gaussian Mixture model에 기반된 Maximum Likelihood classifier, SVM, Conditional Random Field, Markov Random Field 등
dnn을 사용하는 model이 많아져서 point cloud semantic segmentation을 실현하기 위해 고유한 특징을 추출하는 것이 나타났다.
그러나 불규칙하고 구조화가 되지 않은 point cloud때문에 3D data의 deep network의 적용은 막대한 어려움에 직면하고 있다.
우선, researcher들은 처리하기 위해 cnn에 대해 적합한 규칙적인 구조로 point cloud를 변경한다.
하지만 이 방법은 정보 손실, 연산 복잡성과 같은 문제를 겪었다.
최근에, pointNet는 연산 속도도 빠를 뿐만 아니라 segmentation의 성능도 향상되었다.
요즘 pointnet에 기반된 많은 방법이 있다.
raw point cloud을 사용하는 다른 방법은 다양한 지식과 model을 사용한다.
몇몇 point cloud semantic segmentation model은 정확도를 향상시키기 위해 image 처리 알고리즘을 추가한다.

규칙적인 구조로 point cloud를 변환하는 간접적인 방법은 multi-view와 voxel grid에 기반되고 직접적인 방법(point 순서에 기반된 방법, multi-scale에 기반된 방법, feature fusion에 기반된 방법, GCNN의 fusion에 기반된 방법)은 point cloud에 바로 작동한다.
Point cloud semantic segmentaation model based on deep learning
- Indirect way for point cloud semantic segmentation
지금까지 segmentation을 실현하기 위해 규칙적인 규조로 point cloud를 변환하는 두가지 종류의 3D representation(multi-view, voxel grid)이 있다.
1) Multi-view based method
point cloud의 불규칙성때문에, 2D network는 point cloud에 있는 3D application로 확장할 수 없다.
그러므로 간단한 방법은 2D view로 3D data를 변형하는 것과 마찬가지이고, point cloud 처리에 대한 feature를 추출하기 위해 존재하는 지식을 적용한다.
* MVCNN

image에 기반된 multi-view convolutional neural network(MVCNN)를 제시
한편으로는, point cloud와 같은 구조화되지 않은 data에 CNN을 적용한다.
반면에, classification과 segmentation과 같은 task를 효과적으로 완료한다.
이 방법의 주요 아이디어는 multiple 관점에서 2D image에 3D point cloud를 투영하는 것이고, image 처리의 방법을 사용해서 각 view에 대한 feature를 추출하기 위해 CNN을 사용한다.
그리고 view pooling layer를 통해 다른 관점으로부터 추출된 feature를 합친다.
합쳐진 feature는 처리를 위해 CNN에 input한다.
MVCNN은 복잡한 scene보다 개인적 object의 segmentation에 대해 적합하다.
-> object 간 공간 관계를 무시하기 때문
* SnapNet
3D point cloud를 의미하는 projection은 multiple 관점으로부터 2D image로 변형되었고 정보 손실 문제가 발생한다.
-> SnapNet은 RGB와 depth image의 쌍을 생성하기 위해 point cloud의 snapshot을 선택한다.
fcn을 사용해서 각 2D 이미지 쌍에 픽셀 단위로 레이블이 지정됩니다.
task를 달성하기 위해 표시된 point을 3D space에 투영한다.
semantic segmentation의 실현을 돕기 위해 depth 정보를 추가함에도 불구하고 segmentation 정확도에 영향을 주는 문제들이 있었다.
* SnapNet-R
SnapNet은 정보손실 문제를 다루지만 image 생성의 처리에 문제를 마주한다.
SnapNet-R은 snapnet의 기본으로 제안한다.
segmentation의 결과를 향상하는 dense 3D point marker를 얻기 위해 multiple view를 처리한다.
- 표시된 point cloud를 생성하는 과정
1. stero image에서 얻은 RGB-D image의 2D labeling
2. Snapnet을 사용하는 3D labeling
실현하기 쉬운 알고리즘을 가지지만 object boundary의 segmentation 정확도가 여전히 높아질 필요가 있다.
multiple view를 기반으로 point cloud segmentation 방법은 좋은 결과를 냈지만 3D point cloud의 투영이 point cloud segmentation 정확도에 영향을 주는 많이 중요한 geometric 공간 정보를 손실낼 것악흐 투영각에 의해 영향을 많이 받을 것이다.
2) Volumetric method
point cloud의 voxelization은 구조화되지 않은 point cloud를 변형시키는 것과 규칙적인 volumetric occupancy grid로 만드는 것을 의미한다.
point cloud의 semantic segmentation을 하기 위해 neural network를 사용함으로써 feature을 학습한다.
* VoxNet
volumetric 방법을 사용하는 VoxNet는 구조화되지 않는 geometric data에서 기존 CNN 연산에 적용될 수 있는 규칙적인 3D grid로 변경하는 것이다.
그리고 occupancy grid로부터 직접적으로 class label을 예측하기 위해 3D CNN을 사용한다.
-> point cloud의 non structure 문제를 해결
point cloud의 희소로 의해 voxel grid 배치의 낮은 효율성, 연산 과정동안 사용되는 많은 memory, 학습하는 동안 오래 걸리고 정보 손실 문제 등과 같은 단점을 가진다.
* SEGCloud

point cloud의 희소성에 고려해서, sparse convolution network를 design하고 3D segmentation task에 적용한다.
sparse 3D data를 sample하는 것에 시도하고 연산량을 줄이기 위해 처리하는 network에 넣는다.
voxel grid의 공간 해상도 문제를 극복하기 위해, K-d tree나 octree와 같은 공간적 분할의 방법을 소개한다.
-> 이 방법의 결점은 voxel boundary에만 의존하고 local region의 geometric 구조에 집중하지 않는다는 것
SEGCloud는 3D fully convolutional neural network(3D-FCNN)를 사용함으로써 voxel grid로 큰 point cloud를 세분화하고 3D point로 class score를 보간하기 위해서 삼선형 interpolation layer를 이용한다.
최종적으로 CRF는 fine-grained class 분포를 얻기 위해 전처리에 대한 보간 점수로 기존 3D point feature를 결합해서 사용한다.
특정한 task를 달성하기 위해 딥러닝과 머신러닝을 효과적으로 결합하고, semantic segmentation의 분야에 좋은 성능을 보인다.
* PointGrid
PointGrid는 point와 grid로 통합되는 3D convolutional network
섞인 model에서 local geometry의 세부사항을 얻기 위해 고정된 point로 grid cell을 학습하는 3D CNN을 이용한다.
VoxNet과 같은 변형 방법을 사용하지만 더 잘 크기 변화를 나타내고, 정보 손실를 방지하고, 작은 memory를 차지한다.
point cloud semantic segmentation과 target recognition에 대해 통합된 grid kernel에 기반된 3차원 convolution 연산자를 제시
Pointgrid는 학습과 테스트에서 더 간편하고 빠르다.
semantic segmentation의 task를 하기 위해 규칙적인 view와 voxel grid로 point cloud를 변형하는 간접적인 방법은 CNN이 point clouid에 적용되지 않는 문제를 해결하고 좋은 segmentation 결과를 보였다.
하지만 정보 손실, 복잡한 연산, 많은 memory량과 같은 문제를 가지고 있다.
- Directly way for point cloud semantic segmentation
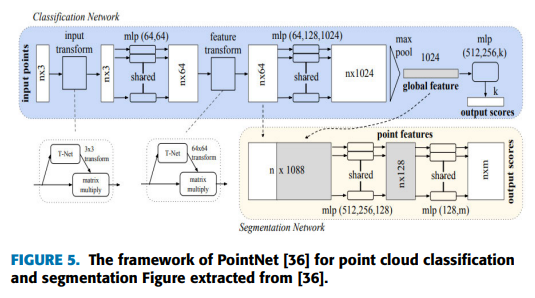
raw point cloud에 기반된 model은 point cloud data의 특성을 충분히 활용하기 위해 제시되고 netowrk의 연산 복잡성이 줄었다.
pointnet은 point cloud의 classification과 segmentation을 처리하는 구조화되지 않은 point cloud에 deep learning을 적용한 선구적인 network 구조이다.
이 framework는 point cloud의 희소, 순서 불변성, 변화 불변성 문제를 다룬다.
point cloud의 희소성을 고려해서 pointnet을 design한 연구자들은 multi-view나 voxel grid로 point cloud를 변형하지 않지만 직접 point를 처리한다.
순서 불변성에 대한 mlp는 각 point에 대해 feature를 추출하고 모든 point의 정보는 maximum pooling layer를 사용함으로써 global feature를 얻기 위해 합친다.
게다가, 변화 불변성의 문제를 풀기 위해 이 framework는 input point cloud와 feature에 할당하는 transformation matrix를 만드는 transformation network를 추가한다.
pointnet은 point cloud classification이랑 segmentation에 유익한 영향을 가짐에도 불구하고 point와 local neighborhood 정보 간 관계를 고려하는 것에 실패했다.
큰 scene에 있는 point cloud를 처리할 때, 중요한 정보의 손실이 있었고 안 좋은 segmentation 결과를 가졌다.
1) method of point ordering
neural network에 기반된 point cloud semantic segmentation의 어려움은 point cloud의 불규칙과 무질서에 있다.
* PointCNN

point cloud의 무질서에 관해서 복잡한 dataset과 어려운 task 둘 다 좋은 성능을 보이는 PointCNN을 제시
PointCNN model의 핵심은 X-Conv operator이다.
X transform은 input point로부터 학습된 가중치 X의 group이고, 재가중치를 주고, 각 point의 연관된 feature를 정리한다.
X transform이 input point로부터 학습되기때문에, 가중치는 input point의 순서에 따라 바뀐다.
제안된 model은 input point 순서로 feature의 변화를 방지하기때문에 바뀌지 않는 X-transformed feature가 남아있다.
- PointCNN의 장점
1. X transformed feature에 적용하는 convolution이 convolution kernel의 활용을 향상시키는 것
2. 무질서된 data에 feature를 추출하기 위해 convolution 연산의 능력을 향상시킨다.
- PointCNN의 결점
이 network로부터 학습된 X-transformation이 완벽하지 않고 point cloud segmentation에 영향을 준다는 것
* RSNet

3D segmentation에 대한 새로운 framework 제시(RSNet)
slice pooling layer, RNN layer, slice de-pooling layer로 구성된다.
slice pooling layer는 불규칙한 point feature를 RNN에 적용하는 규칙적인 순서를 가지는 feature vector에 투영하는데 사용된다.
RNN은 feature vector 간 관련성을 시뮬레이션하기 위해 실행된다.
slice de-pooling layer는 point cloud segmentation의 task를 하기 위해 point로 sequence에 있는 feature를 할당한다.
model의 특성은 XYZ의 feature vector를 추출하고, 전처리를 위해 순서가 있는 feature sequence를 출력하는 것이다.
이 model은 point cloud 불규칙성의 영향을 완화하고 point cloud semantic segmentation에 있는 더 나은 성능을 달성한다.
* SO-Net

SO-Net은 point의 위치를 바꾸고 효율적인 point cloud의 segmentation을 실현하기 위해 self organizing mapping을 구현함으로써 point cloud의 공간 분포를 시뮬레이션하는데 사용되는 순서 불변성의 특징을 처리하는 model이다.
게다가 다양한 task에서 network 성능을 향상시키기 위해, pretraining으로써 auto encoder로 point cloud를 제시
그러나 큰 scene에 있는 엄청난 양의 point cloud data와 scene의 엄청난 복잡성때문에, 많은 제약이 있었다.
point 순서를 기반으로 제안된 model은 기존 방법과 비교하여 point cloud의 무질서를 해결하고 처리 속도를 가속화하며 포인트 클라우드 의미론적 분할에 더 큰 기여를 할 수 있습니다.
그러나 이러한 방법은 다른 측면에서 문제가 발생할 수 있습니다. 예를 들어 encoder는 세분화된 구조를 캡처할 만큼 강력하지 않습니다.
2) Method based on multi-scale
deep learning의 발전으로, 연구자들은 object의 feature를 추출하기 위해 cnn을 사용했다.
receptive field는 segmentation task에서 더 중요하게 되었다.
receptive field가 너무 작으면 local feature만 얻어졌다.
너무 크면 결과에 영향을 받는 유효한 정보를 많이 포함한다.
* PointNet++

PointNet++는 sampling layer, grouping layer, pointnet layer로 구성된다.
model은 FPS를 사용함으로써 local area의 중심점으로서 input point로부터 여러 point를 선택한다.
그리고 local region을 만드는 기존 network에 기반된 grouping module로 local region을 추가한다.
PointNet은 local feature를 추출하기 위해 사용됐다.
model은 local feature를 추출 문제를 효과적으로 해결하고 segmentation의 결과를 향상함에도 불구하고 point set에서 여전히 point를 독립적으로 처리하고, 거리와 방향같은 point 간 관계를 고려하지 않는다.
* 3DMax-Net

3DMax-net은 multi-scale의 아이디어를 채택한다.
구조는 매우 간단하고, MS-FLB와 LGAB 두 핵심 파트로 구성된다.
model에서 multiple scale에서 학습된 feaute를 먼저 융합하고 segmentation의 정확도를 향상하기 위해 병합하는 local feature과 global feature를 합한다.
MLP는 task를 실현하기 위해 각 point 점수를 연산합니다.
MS-FLB: multi-scale feature learning block
LGAB: local feature과 global feature을 합하는 block
model은 다른 scale에 대해 학습된 feature를 합하고 더 나은 성능을 보인다.
* 3P-RNN

point cloud semantic segmentation의 성능을 향상시키기 위해, 다양한 scale에서 local neighborhood의 feature를 합치기 위해 활용하는 point별 pyramid pooling module을 제시
hierarchical two direction RNN은 multiple level으로 semantic feature의 fusion을 달성하기 위해 공간적인 context 정보를 학습했다.
-> 공간 정보를 고려하고 어려운 indoor, outdoor 3D dataset 둘 다 segmentation에서 높은 정확도를 나타낸다.
multi-scale에 기반된 방법은 2차원 image 처리의 knowledge로 이루어졌고, object의 scale에 따라 feature를 추출하기 위해 receptive field를 조절한다.
target object의 크기에 상관없이 segment되었고 fine feature를 capture했다.
-> 개선이 필요한 약간의 결점이 있다.
3) Method of feature fusion
Feature fusion은 point cloud semantic segmentation을 향상하기 위해 network로부터 얻어진 local feature과 global feature를 결합한다.
pointnet의 model은 local region의 특성을 고려하는 것 없이 semantic segmentation을 달성하기 위해 point cloud의 global feature를 추출한다.
* PointNet

3D scene의 이해를 달성하기 위해 pointnet과 pointnet++ 둘 다 feature를 추출하는 raw point cloud를 사용한다.
point cloud에서 shape feature의 묘사는 point cloud segmentation의 결과를 향상시키는 중요한 역할이다.
2D image에 사용된 Scale invariant Feature Transform(SIFT)에 영감을 받아서, PointSIFT module을 design했다.
PointSIFT module은 direction coding unit에서 8개의 주요 direction 정보를 encode하고, 다양한 feature을 얻기 위해, 여러 direction coding unit을 쌓는다.
model은 3D point cloud에 2D image 처리의 knowledge를 도입하고, segmentation task에 scene의 local feature를 얻는다.
* A-CNN
hierarchical neural network에 annular convolution을 적용하는 A-CNN은 큰 scene의 semantic segmentation을 달성하는 것이다.
annular convolution의 function은 각 point 근처 local neighborhood의 geometric feature를 추출하는 것이다.
dilated convolution에 영감을 받아서 model에 제시된 annular convolution은 object의 세부사항을 더 낫게 capture하는 dilated ring의 형태를 쓴다.
feature fusion 방법은 segmentation의 결과를 향상시키기 위해 local feature과 global feature를 결합한다.
* SpiderCNN
feature fusion에 기반된 많은 방법은 큰 scale의 point cloud scene을 처리하기 위해 제안됐다.
SpiderCNN은 일련의 convolution filter를 parameter화함으로써 point의 불규칙한 set에 규칙적인 grid에 convolution 연산을 확장하는 SpiderConv라고 불리는 unit으로 구성된다.
-> scene에서 point cloud로부터 효과적으로 geometric feature를 추출한다.
feature fusion을 사용함으로써 제시된 model에 따라 deep learning 방법은 다른 scene의 local과 global feature를 얻을 수 있다.
그리고 segmentation의 결과를 향상시키기 위해 융합한다.
이 방법은 간접적인 방법에 의해 일어난 문제를 해결하고 artificial feature에 기반된 전통적인 방법에 중요한 장점을 가진다.
4) Method of fusing GCNN
Graph는 일련의 node와 edge로 구성된 구조화된 data의 type이다.
요즘 node 간 정보를 변환함으로써 graph의 의존성을 capture하고 graph structure에 직접적으로 사용되는 graph convolutional neural network(GCNN)는 computer vision 분야에서 일반적으로 사용된다.
* DGCNN
point cloud의 과정에 GCNN을 처음으로 적용했고 point cloud의 semantic segmentation을 실현하기 위해 PointNet과 GCNN을 결합했다.
DGCNN은 graph CNN에 의해 영감을 받았지만 중요한 차이는 구축된 graph는 역동적이고 각 network의 각 layer 다음 update된다는 것이다.
edge convolution 연산은 주로 center point의 feature를 추출하기 위해 design됐다.
center point의 edge vectore와 KNN point를 얻을 수 있다.
network의 architecture는 pointnet과 비슷하고, DGCNN은 edge convolution을 쌓는 multi-layer perception만 대체한다.
이 알고리즘은 feature space에 있는 analogous feature를 cluster할 뿐만 아니라 Euclidean space에 있는 neighborhood를 찾고, point cloud classification과 segmentation의 task에 중요한 영향을 준다.
* LDGCNN

DGCNN model에서, space transform된 network를 소개하는 것은 network의 복잡성을 증가시키고 학습하기 위해 network에 있는 parameter는 증가한다.
DGCNN의 기반으로 기존 model을 변형해서 DenseNet의 network 구조를 채택하고, 앞에서 언급된 문제를 다루기 위해 LDGCNN을 제시했다.
model의 기존 idea는 다양한 dynamic graph로부터 추출된 hierarchical feature를 연결하는 것이고, transformation network를 MLP로 바꾼다.
-> gradient 사라짐 문제를 방지, network 크기 감소, point cloud의 dataset에서 우수한 semantic segmentation 결과를 달성
* RGCNN
GCNN을 사용함으로써 point cloud segmentation을 하는 다른 방법은 RGCNN이다.
RGCNN은 graph construction, graph convolution, feature filtering을 포함하는 3개의 regular graph convolutional layer로 구성된다.
dynamic graph 구조를 포착하는 것의 목적은 inter-layer feature 관계를 묘사하기 위해 graph Laplacian matrix를 design하는 것이다.
동시에, matrix는 학습된 관련 feature에 따라 update된다.
GCNN을 융합하는 model은 point cloud의 permutation invariance의 문제를 다룰뿐만 아니라 point cloud에 있는 밀집도와 noise에 강력한 robustness를 가진다.
* GAPNet

resource를 처리하기 위해 visual 정보를 적절하게 사용하고 unman perception을 위해 더 적합한 결과를 얻는 방법에 대한 문제는 연구 주제이다.
이 문제를 극복하기 위해, input으로서 visual 영역의 특정한 부분을 선택하는 것과 중요한 영역에 정보를 처리하기 위해 제한된 resource를 집중하고 할당하는 것인 두 필수적인 측면인 attention 매커니즘을 제시한다.
요즘 이 기술은 점차적으로 발전하고 point cloud의 segmentation을 위해 GCNN과 결합했다.
GAPNet은 local geometric 정보를 학습하기 위해 쌓여진 multi layer perception에 graphical attention 매커니즘을 embed하는 point cloud의 새로운 neural network이다.
Pointnet과 비슷하다.
중요한 차이는 GAPLayer가 neighborhood에 있는 다른 attention weight를 강조함으로써 각 point의 attention 특성을 학습하기 위해 도입된다는 것이다.
게다가 model을 위해 충분한 feature를 제공하기 위해. multi-head 매커니즘은 다양한 GAPLayer로부터 얻어진 feature를 합하기 위해 추가됐다.
point cloud의 효과적인 segmentation을 하기 위해, GAPNet은 attention feature과 local geometry의 정보를 추출하는 local 특징에 있는 쌓여진 MLP layer에 적용한다.
model은 point cloud segmentation에 있는 human visual system에 있는 attention 매커니즘을 추가하고 scene을 잘 분할한다.
GCNN은 semantic segmentation를 하기 위해 point cloud에 널리 사용되고, 좋은 segmentation 결과를 달성한다.
GCNN에 기반된 방법은 point간 관계를 검토할 뿐만 아니라 boundary feature를 가지는 것을 다른 방법과 비교한다.
point cloud를 처리하는 segmentaiton 방법은 point cloud의 segmentation에 대해 더 좋은 결과를 냄에도 불구하고 학습하는 동안 많은 양의 data가 필요하고 GPU의 computing 성능이 더 좋아야 한다.
Related dataset of point cloud semantic segmentation
- Dataset
1. PartNet
2. UWA dataset
3. ShapeNet part
4. S3DIS
5. ScanNet
6. Semantic3D
7. vKITTI
8. KITTI Raw

Analysis of experiment result
- model의 성능을 판단하는 척도
1. 실행시간
2. 공간 복잡도
3. 정확도
-> mean Intersection over Union(mIoU), overall accuracy(OA)
'survey' 카테고리의 다른 글
| Vision-Language Models for Vision Tasks: A Survey (1) | 2024.09.11 |
|---|---|
| Image Segmentation Using Deep Learning: A Survey (0) | 2024.06.24 |
| A Survey of Deep Learning Techniques for Autonomous Driving (0) | 2024.04.24 |
| A survey: object detection methodsfrom CNN to transformer (0) | 2024.03.28 |