Abstract
Alexnet 이후에 CNN에 기반된 방법은 computer vision 분야에 주요 방법이 되었다.
빠르고 정확한 detection 효과를 가지기 위해서, CNN framework를 뛰어넘는 것은 필수적이고 큰 도전이다.
transformer의 방법은 computer vision task에 사용할 수 있는 것을 증명했고, CNN 방법을 능가한다.
computer vision task에 Transformer를 사용하는 최근 혁신적인 방법을 제시
Introduction
object detection의 task와 목표는 직사각형의 bounding box를 가지는 주어진 image에 있는 object category와 위치를 올바르게 분류하는 것이다.
1. 전통적인 object detection 방법(VJ detector, HOG 등)
2. 현재 CNN 알고리즘
전통적인 방법 -> 연산량이 크기때문에 속도가 느려서 안 좋다. 게다가 우리가 원하는 결과 대신 많은 인식 결과가 나와서 현재 사용을 충족 X
two stage detection 방법은 속도가 느리고, one stage detection 방법은 정확도가 떨어지고 transformer 기반된 detection 방법은 많은 training data가 필요하다.
이런 문제를 해결하기 위해 어떤 idea가 있는지 어떻게 이러한 제한이 생기는지 문제를 해결하는 것은 중요하다.
현재, CNN 알고리즘은 일반적인 target detection 방법과 특별한 object target detection 방법 둘 다 절대적인 위치를 가졌다.
그러다가 NLP가 사용된 transformer를 사용하기 시작됐고, CNN에 완전히 대체되는 경향을 보였다.

Background
object detection은 image에 있는 target을 분류하는 것뿐만 아니라 object를 locate한다.

- Multi-scale object detection model
큰 object는 큰 영역의 특성, 좋은 feature가 있어서 detect하기 쉬운데 dense object와 작은 object는 사용가능한 feature가 작아서 detect하기 어렵다.
multi-scale object detection 방법의 목표는 image에 있는 다양한 scale의 모든 object를 detect하는 것이다.
- Real-time object detection model
real-time object detection model은 memory 요구량, 연산량을 고려해야하고, detection 성능과 real-time 필요조건을 균형 맞춘다.
좋은 결과인 YOLO series를 제외하고 다른 알고리즘은 lightweight network에 노력을 기울였다.
- Weakly-supervised detection model
weakly-supervised object detection task는 image level label은 주어지고 object boundary annotation box가 부족한 training sample로 적용된다.
이 detection model의 성능은 label된 training sample의 수에 의해 결정된다.
그러나, object의 bounding annotation box는 시간과 노동때문에 supervise된 training sample을 얻기 어렵다.
게다가 rare object class의 작은 개수때문에 training set에 적거나 없는 sample은 해당 class를 detect 할 수 없다.
그래서 weakly supervised, few shot, zero shot object detection 연구가 활발히 진행됨
- Solve imbalance of training samples in object detection model
Unbalanced training sample은 detection 연구에서 문제다.
최근에, 많은 연구들은 training sample의 sampling 방법이나 loss function에 sample의 weight를 조절해서 향상시키고 sample 간의 관계를 연구함으로써 unbalanced 문제를 해결하고자 한다.
Object detection
- object detection 알고리즘의 feature extraction 두가지 방법
1. CNN에 기반된 object detection
2. transformer에 기반된 object detection
* Convolutional neural networks used on object detection
- Detection model의 두가지 핵심 문제
1. object classification
2. object positioning
detection system은 object의 interest를 가지는지 아닌지 먼저 결정하고 object category를 확인하고 object의 카테고리 score를 출력한다.
feature map: image에 있는 convolution kernel에 작용함으로써 얻어진 새로운 image
feature map에 있는 receptive field의 크기는 기존 image의 영역이 high level feature map에 있는 pixel에 영향을 받는 정도와 동일하다.
- object detection 알고리즘의 두가지 type
1. one stage object detection
2. two stage object detection
- Two stage algorithms(candidate-based algorithms)
- two stage 알고리즘 2단계
1. image로부터 후보 region을 추출한다(region proposal)
2. 결과를 얻기위해 region proposal을 분류하고 위치하기 위해 CNN을 사용
two stage 알고리즘은 상대적으로 정확도 \uparrow, detection 속도 \downarrow
ex) R-CNN, SPP-Net, Fast R-CNN, Faster R-CNN
1) R-CNN(Region-CNN)

selective search: region proposal 추출
SVM: region proposal clssification
- R-CNN 과정
1. input image
2. 2000개 region proposal 추출
3. region proposal 넣고 CNN feature 연산
4. classification을 결정하기 위해 SVM 사용
- 단점
1. training time 오래걸림 -> 이유: 많은 stage 수행하고, 다양한 후보 region의 feature map이 각각 연산돼서
2.공간 연산 큼
3.test time 길다. -> 이유: 각 region proposal의 feature map 연산은 각각 연산되고 공유되지않아서 연산량이 많아서
2) SPP-NET(Spatial Pyramid Pooling Network)



SPP-Net은 고정된 size의 input image를 사용하지 않고, convolutional layer에 전체 image를 사용한다.
black feature map은 image가 convolutional layer를 지나고 나서 얻어진다.
input feature map은 다양한 scale(4*4, 2*2, 1*1)의 block으로 나눈다.
max pooling은 각 block에 사용된다.
16+4+1의 고정 길이를 가지는 vector가 된다.
그러므로 다른 scale의 image가 input인 이후에 SPP layer를 지나간 후 같은 길이의 vector를 얻을 수 있다.
- R-CNN의 multi stage process 상속
- 2000개의 후보 region을 추출하기 위해 selective search 방법을 사용
- feature map을 추출하기 위해 CNN network 사용
- input은 classification에 대한 SVM에 있는 feature를 추출했다.
- SppNet의 혁신
1. 모든 region proposal에 대한 feature extraction의 반복을 피하기 위해서 CNN에 전체 image를 넣는다.
2. SPP-Net layer를 사용한 후, model은 image의 다양한 scale을 쓸 수 있다.
- SPP-Net의 한계
1. SPP-layer 전에 있는 network의 parameter를 fine tune하기 어렵다.(효율성이 너무 낮기 때문)
2. 각 training sample(Roi)을 fine tuning하는 것이 다른 image에 될 때, SPP layer의 backpropagation 효율성은 매우 낮다.
(각 image에 대해 새로운 feature map을 다시 만들기 때문)
3) Fast-RCNN
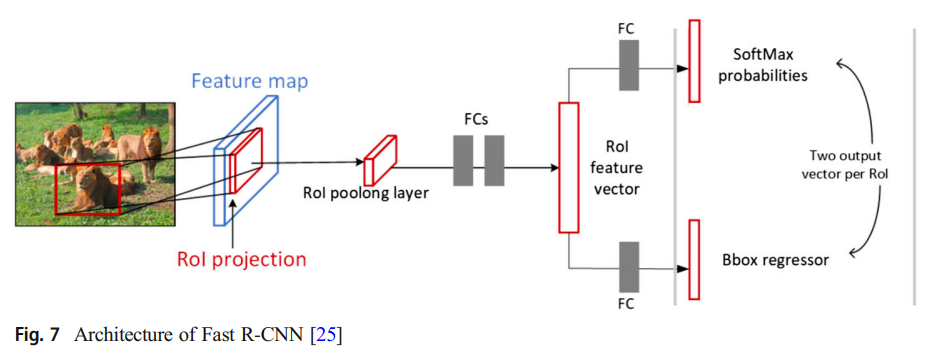
여전히 training step이 너무 많고, hardware 연산이 크다.
Faster(오타인듯) R-CNN과 SPP-Net과 비교하면, training speed가 전자보다 9배 더 빠르고, 후자보다 3배 더 빠르다.
- RCNN에 기반해서 향상된 Fast RCNN
1. 마지막 convolutional layer -> Roi pooling layer
2. Multi-task Loss는 training에 대한 network에 bounding box regression 추가
region proposal classification loss와 position regression loss를 포함
3. classification에 대해 SVM -> SoftMax
network에 bounding box regression을 추가하기 위해 Multi-task Loss를 사용
전체 training은 후보 region 추출과 cnn training의 two stage만 포함
- Fast R-CNN 한계
region proposal의 추출은 selective search를 사용하는 것이 주요 한계
대부분 object detection 시간은 region proposal에 쓰인다.
4) Faster R-CNN

selective search 알고리즘 대신, Region Proposal Network(RPN) 사용
RPN은 큰 크기로 상관없는 region proposal을 줄이고, model의 image 처리 속도를 향상시킨다.
RPN은 region proposal을 생성하기 위해 cnn을 사용한다.
object boundary와 각 boundary box의 score를 동시에 예측한다.
RPN은 end to end 최적화를 하기 위해 Fast R-CNN과 동시에 학습된다
- 개선사항
1. 각 region proposal을 분류하기 위해, 큰 연산이 여전히 필요하다
2. 이전 object detection 알고리즘과 비교하면, 속도가 많이 향상됐지만 실시간 detection 결과는 아직 아쉽다.
- 한계
1. one stage 알고리즘에 비해, 속도가 느리다
2. background 오탐률이 높다
(몇몇 negative sample은 학습에 사용되고 background learning이 충분하지 않기 때문)
3. NMS는 가려진 object에 적합하지 않다
- One stage algorithms(regression based algorithms)
one stage 알고리즘은 미리 region proposal을 만드는 것 없이 image에 있는 object의 positioning 좌표와 classification 확률을 바로 만든다.
덜 계산집약적인 단계여서 detection 속도가 빠르다.
1) YOLO series
YOLO는 image를 한번 보고 빠른 속도로 image에 있는 target을 detect한다.
핵심 idea는 object detection task에 있는 region proposal 생성과 detection의 두 step을 결합하는 것이다.
- YOLOv1
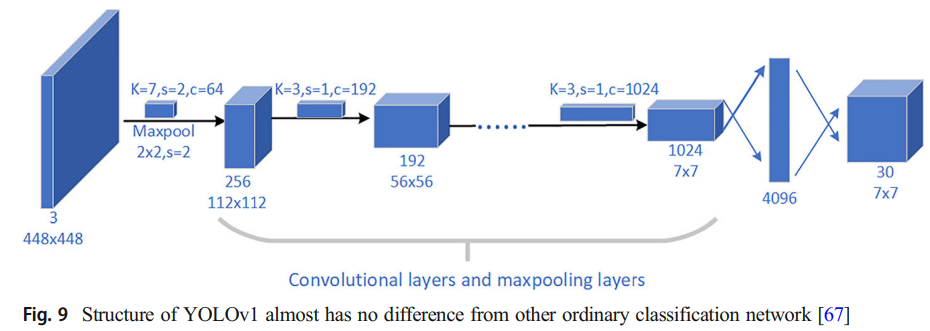
convolution, pooling, full connection이 model 끝에 추가된다.(CNN object classification model과 비슷)
CNN classificaion model과 차이점은 마지막 output layer에 있는 activation function으로 linear function을 사용한 것이다.
왜냐하면 object의 class를 예측할 뿐만 아니라 bounding box의 position을 locate하기 때문이다.
- 장점
1. classification과 positioning을 동시에 진행
2. 강한 일반화와 다른 분야에서 확장할 수 있다.
- 단점
1. 많은 object가 가까이 있다면, object는 상대적으로 작고 detection은 잘 안될 것이다.
2. 같은 object의 다양한 shape에 대한 일반화 능력이 떨어짐
3. loss function때문에 detection에 영향이 있는 주요 이유는 positioning error이다.
- YOLOv2
Darknet-19: 19 convolutional layer와 5 max pooling layer
YOLO9000: 약 9000개의 object type를 detect
더 이상 각 convolutional layer 뒤에 dropout이나 batch normalization layer를 사용하지 않는다.
YOLOv2, YOLO9000 둘 다 주요 구조가 같다.
- YOLOv3
가장 큰 다른점: residual module과 FPN architecture 사용
Darknet-53: 53 convolutional layer(residual model)
FPN architecture(multi scale detection하기 위해)
- YOLOv4
data processing, network training, activation function, loss function 등과 같은 많은 방법으로 향상된다.
이론적인 혁신은 없었음에도 불구하고 환영받음(?)
- 기여
1. 일반적인 GPU에서도 고효율, 고정확도 obejct detection model을 제공
2. SOTA target detector training method의 영향을 입증
3. FPS와 Precision 간 balance를 맞추는 target detection에 대한 new benchmark에 도달했다.
- YOLO의 다른 version의 한계
- YOLOv1:
작은 target의 detection은 매우 안 좋다. 각 cell당 2 box만 만들 수 있고, 하나의 class만 가져서 recall율이 낮다.
- YOLOv2:
많은 trick이 performance를 향상시킴에도 불구하고, 작은 object에 대한 detection은 잘 향상되지 않았다.
- YOLOv3:
two stage 알고리즘(R-CNN 계열)에 비해, 정확도는 여전히 부족
같은 output layer, 같은 anchor에 먼저 있는 data가 나중에 overwritten될 것이다. -> 같은 위치에 비슷한 size가 있으면 하나만 인식한다는 뜻
- YOLOv4: 많은 trick을 사용해서 성능을 향상시킨다.
2) SSD(Single Shot Multibox Detector)

이 알고리즘이 detection task에 혁신적인 multi scale feature map을 적용할 때, 새로운 target detection 알고리즘은 multi scale의 개념을 더 사용하거나 덜 사용하는 것에서 제안됐다.
object의 positioning은 local 정보에 관련되어 있고 shallow feature map에서 표현됨.
object classification은 segmentation 정보에 관련되어 있고, deep feature map에서 표현됨
multi scale feature map에 있는 convolution은 detection accuracy를 향상시킴
SSD는 YOLO의 detection 속도를 유지하고 Fast-RCNN의 정확도를 유지한다.
-> YOLO의 regression idea, Fast-RCNN의 anchor 매커니즘을 사용하고 regression으로 image의 다양한 position에 있는 multi-scale region을 사용하기 때문
VGG의 처음 5개의 convolution을 사용하는 VGG-16에 기반됨으로써, Conv6로 시작하는 5개의 convolution 구조를 추가하고 input image는 300x300으로 넣는다.
mAP: 74.3%
speed: 59FPS
input image의 해상도가 낮아도 결과가 여전히 좋았다.
- SSD의 한계
1. 작은 size, 큰 size와 이전의 box의 aspect ratio값은 수동으로 설정해야함
2. 작은 object를 detecton하는 것이 여전히 힘듦
3) RetinaNet

one stage object detection에서 낮은 정확도 문제는 positive와 negative sample의 불균형이 원인이다.
그래서 균형을 맞춰주기 위해 cross entropy loss function 대신에 focal loss를 사용했다.
Retinanet은 Faster R-CNN처럼 높은 정확도를 보였다.
Focal loss의 방식은 고정적이지 않고 다른 형태가 가능했지만 성능은 큰 차이 없었다.
Resnet + FPN의 결합으로 Retinanet을 만들었다.
feature extraction을 위해 backbone으로 Resnet을 선택했고 FPN은 multi scale target region 정보를 포함하는 feature map을 얻기 위해 resnet에 형성된 multi scale의 활용을 향상시켰다.
focal loss는 positive와 negative sample 간 imbalance를 많이 완화했지만 방해에 영향을 받기 쉽기 때문에, sample의 올바른 labeling은 힘들다.
4) CenterNet

CenterNet: CornerNet에 기반으로 제안된 새로운 anchor free detection 방법
object frame의 왼족 위 corner와 오른쪽 밑 corner를 예측하는 것은 어렵다.
-> 대부분 object에서, 두개의 corner point는 object의 밖에 있고, 두 개의 corner point의 embedding vector는 object의 내부 정보를 인지할 수 없기 때문
Cascade Corner Pooling은 기존 Corner pooling을 대신해서 사용함
1. object boundary(Corner Pooling)의 최대 값을 추출
2. 연속해서 bondary에 있는 최대값을 추출
3. 많은 internal information을 결합하기 위해 boundary의 최대값을 더한다.
- 단점
training과 prediction 과정에서, 두 object의 중심 점이 downsampling 후에 겹친다면, centernet은 하나의 중심점만 detect하고 두 object를 하나의 object로 간주한다.
- Object detection with transformer
2012년에 Alwxnet으로 CNN은 CV task의 분야에서 절대적이였다.
많은 연구로 다양한 방법이 나왔는데 그 중에서 NLP 분야에서 attention 매커니즘과 CV 분야에서 CNN으로 CNN 단점을 보완한 Transformer가 자리잡아 사용됐다.
- Transformer history
DETR, D-DETR: classification과 instance segmentation를 위해 Transformer와 CNN의 결합을 사용한 model
ViT: classification을 위해 순수 transformer를 사용한 transformer에 기반된 computer vision model
Swin Transformer: ViT의 idea로 새로운 universal backbone
1) Detection Transformer(DETR)

Resnet50에 기반된 DETR은 다양한 finetuning 후에 Faster-RCNN의 성능과 비슷했다.
- DETR architecture
1. CNN backbone network
2. Encoder-decoder transformer
3. 간단한 feedforward network
CNN backbone network는 input image로부터 feature map을 만든다.
그 후 CNN backbone network의 output은 1차원 feature map으로 변환되고 input으로 Transformer encoder를 통과한다.
encoder의 output은 N개의 고정된 길이 embedding이다.
N: model에서 추정하는 image에 있는 object의 수
Transformer decoder는 encoder-decoder attention 매커니즘을 사용해서 bounding box 좌표로 embedding을 decode한다.
마지막으로, 정규화된 중심 좌표, bounding box의 height(세로), width(가로)는 feedforward neural network로 예측되고, linear layer는 category label을 예측하기 위해 Softmax function을 사용한다.
- DETR의 장점
1. object detection을 위한 다른 계획 제안하고 이전 정보가 덜 필요하다
2. 정확도와 효율성이 아주 높지않음에도 불구하고 아주 최적인 Faster R-CNN에 맞먹고 detection이 큰 object에 더 잘 된다.
3. custom layer를 필요로 하지 않아서 model을 다시 만들기 쉽고 module은 deep learning framework에 있다.
- 단점
느린 수렴속도, detection 정확도 안 좋음, 낮은 작동 효율
2) Vision Transformer(ViT)

ViT의 주요 task는 classificaiton task를 하는 것이다.
핵심 idea는 classification을 하기위해 Transformer encoder 부분을 사용하는 것이다.
NLP처럼, classification token은 image sequence를 추가할 것이다.
image sequence는 많은 patch로 image를 잘라서 얻어진다.
patch의 수(N) = HW/P^2
H: image의 height
W: image의 width
P^2: 각 image patch의 해상도
간단한 설정의 장점은 확장가능한 NLP transformer architecture와 효과적인 구현이 거의 즉시 사용되는 것이다.
image가 patch로 잘려졌을 때, linear projection과정에서 정보가 없어졌기 때문에 각 patch의 location 정보가 transformer encoder로 보내지기 전에 추가되어야한다.
분석된 image에 독립적이고 전체 image에 대한 global 정보를 나타내는 다른 vector를 추가한다.
patch에 해당하는 output은 MLP를 지나고 MLP는 prediction class로 반환된다.
그러나, patch에서 vector로 변환하는 동안 patch에 있는 pixel의 위치에 대한 정보가 사라진다.
- ViT의 단점
1. 많은 data가 필요함
2. 많은 연산량
3. embedding location을 encode하지 못한다
3) Swin ViT

ViT 말고 image classification에 Transformer를 사용하는 iGPT라는 model이 있다.
- iGPT 단점
1. image는 내용을 표현하기 위해 적어도 몇 백 pixel이 필요하다.
sequence에 있는 많은 pixel을 처리하는 것에 Transformer는 좋지 않다.
2. Transformer는 detection 문제에 더 좋은 답을 찾지만 instance segmentation의 dence prediction scene을 찾는 능력은 더 향상되어야 한다.
classification, detection, instance segmentation에 sota 결과를 달성해서 transformer가 visual task에 쓰일 때, 최근에, swin transformer는 보편적인 backbone이 되었다.
Swin Transformer는 input image로 작게 resize된 image를 사용하지 않지만 resize에 의한 information loss가 없기 때문에 원래 image를 input한다.
swin transformer의 장점은 CNN에 있는 계층적인 network 구조를 일반적으로 사용하는 것이다.
계층적인 network가 깊어지면 node의 receptive field가 확장된다.
swin transformer는 object를 detect하고 segment하는 능력을 가진다.
- 장점
1. CV 분야에서 transformer의 더 빠른 landing을 달성
2. swin transformer는 Transformer와 CNN의 장점을 결합하고 계층적인 구조는 해상도를 낮추고 channel의 수를 증가시킨다.
3. 다른 visual task에서 Sota를 달성
- 단점
1. 연산량이 중요하다.
2. GPU memory가 많이 필요하다
3. 정확한 fine tuning은 몇몇 프로젝트 응용에 필수다.
4) Twins
Twins는 Twins-PCPVT, Twins-SVT 두 새로운 architecture를 제시
1. Twins-PCPVT

Conditional positional encoding이 있는 PVT에서 positional coding을 대체한다.
conditional position coding(CPE)가 길이 변동이 심한 input을 도와주기 때문에, visual Transformer는 다양한 공간 크기로부터 feature를 처리할 수 있다.
PVT는 CPVT의 conditional position coding 향상을 통해 swin의 성능을 능가하거나 비슷하다는 것을 보여준다.
결과는 왜 PVT 성능이 부적절한 position coding의 사용을 하는 swin에 밀리는지 이유를 확인할 수 있다.
다양한 해상도를 다루는 CPE같은 position code는 downstream task에서 좋은 결과를 가진다.
2. Twins-SVT

현재 global attention의 세부적인 분석에 기반된 attention 방법을 최적화하고 향상시킨다.
새로운 방법은 local global attention 매커니즘을 통합한다.
깊이 분리형 convolution과 달리, 공간 분리형 self attention은 각 그룹의 self attention을 계산하기 위해 feature의 공간차원을 분류하는 것이다.
그리고 global fusion에서 attention 결과를 분류하는 것을 한다.
- 개선사항
training 단계는 image의 고정된 input size를 필요한다.
- The latest object detection research
convolution에 기반된 object detection 방법의 정확도는 feature extraction backbone network에 주로 의존한다.
좋은 backbone은 훌륭한 object detection 방법으로 design된다.
Densenet(backbone) = STDN, DSOD, TinyDSOD
device을 위한 경량화 network = Squezzenet, moblienet, moblienetv2, moblienetv3,
thundernet, shufflenet, shufflenetv2, peleenet, mnasnet
CNN 기반된 backbone network와 다양한 기술을 사용 = Convnet, YOLOX
transformer에 기반된 object detection 방법에 기초한 다른 방법 = Focal Transformer, CSWin Transformer, CBnetv2, mobile ViT
transformer를 사용한 다양한 방법: SegFormer, MaskFormer, TransGAN, TNT, DVT, YOLOS
CNN과 transformer에 기반된 방법: CenterPoint(3D object detection), O2DETR(remote sensing monitoring), SSPnet(small object detection) 등
Comparison
- Data comparison
- object detection task에 사용된 data set
1. PASCAL VOC
2. ILSVRC
3. MS-COCO
4. Open Images
- model 성능을 평가하는 기준
1. precision: model이 예측한 positive sample 중에 true positive sample의 비율
2. recall: 전체 positive sample로부터 model에 예측된 positive sample 수
3. IoU: 합집합과 예측된 bounding box와 ground truth 간에 겹치는 비율
4. FPS: network가 초당 detection 할 수 있는 image 수
5. AP: 다른 recall에서 평균 detection precision 비율
6. mAP: 모든 카테고리로 학습된 model의 품질(모든 AP의 평균)


mAP는 detection model에서 성능을 비교하기 위해 사용되는 대부분 지표이다.




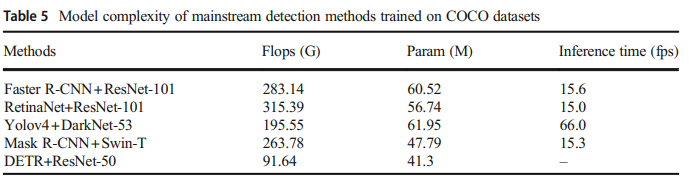
Future trends
- Lightweight detector
detection의 속도를 계산하는 것을 빠르게 하는 것과 mobile device에 실행하도록 하는 것이 목적이다.
하지만 현재 lightweight detection 알고리즘은 여전히 불만족스러워서 lightweight, 빠르고 높은 precision은 target detection에 영원한 숙제이다.
- Multi-task learning

low single tak learning과 detection 성능의 현재 문제를 해결하기 위해, netwok에 있는 multiple task와 network의 multi-level feature를 결합하는 multi task learning 방법은 detection 성능을 향상시키고 동시에 많은 computer vision task를 한다.
- Weakly supervised object detection
deep learning에 기반된 detection 알고리즘의 training은 대량의 고품질 image에 의존하고 model training 과정은 시간 소모가 크고 비효율적이다.
weakly supervised object detection의 사용은 detection 알고리즘이 training동안 label된 dataset bounding box의 부분을 사용할 수 있다.
그러므로 weakly supervised 기술은 cost를 줄이는 것이 중요하고 detection flexibility를 향상시킨다.
- GAN-based object detection
cnn이든 transformer에 기반되는 것은 학습할 때 엄청난 image data가 필요하다.
data를 늘리기 위해 gan을 사용해서 fake image를 만든다.
detector가 강력한 robustness와 일반화 능력을 가지기 위해서 GAN으로 만들어진 data와 실제 data를 섞는다.
- Small object detection
image에 있는 작은 object를 detect하는 것은 오랜시간동안 문제다.
그래서 작은 object의 문제를 푸는 것은 현재 hot topic이다.
ex) 야생 동물의 수 세기, 중요한 군사 target의 상태 detect
- Multi-modal detection
depth camera, lidar, 등 다른 sensor의 사용은 지난 몇년동안 진행됐다.
자율주행 분야에서, 차는 정확하고 robust 환경의 인지를 위해 sensor의 복잡한 array를 가진다.
다양한 유형의 sensor를 서로 보완하고, 인지를 하기 위해 sensor를 융합하는 것은 여전히 해결되지 못했다.
- Video detection
고화질 video에서 실시간으로 object detection/tracking은 video surveillance와 autonomous driving에 중요하다.
존재하는 object detection 알고리즘은 video frame 간 상관관계를 무시하면서 single image에 object detection으로 구현되었다.
video frame의 sequence 간에 공간적이고 시간의 상관관계를 분석함으로써 detection 성능을 향상시키는 것은 연구 방향에 중요하다.
Conclusion
지난 10년동안 object detection task의 주요 연구 내용은 CNN이였다.
하지만 최근의 새로운 방법인 Transformer로 대체됐다.
- object detection task에 CNN과 transformer의 적용에 대한 생각
1. CNN은 높은 level 추상적인 feature를 추출하기 위해 convolution kernel을 사용한다.
이론적으로 receptive field는 전체 image에 다뤄져야하지만 많은 연구는 실제 연구의 receptive field가 receptive field보다 더 커서 contextual information의 사용을 하는 feature extraction에 적합하지 않다.
반면에 transformer의 장점은 global contextual information을 모으기 위해 attention을 사용하는 것이고, 더 많은 feature를 추출하기 위해 object에 long range dependency를 만든다.
2. CNN은 inductive bias와 transitional invariance의 특성을 가지기 때문에, image 문제를 다루기 쉽다.
transformer는 feature를 가지지않고, image feature를 학습하기 위해 학습 model은 많은 data나 훨씬 더 강력한 data 향상을 필요한다.
3. 현재는 CNN과 Transformer를 합쳐서 사용한다.
ViT의 hybrid 구조는 ViT에 feature map을 넣어서 CNN을 사용해서 transformer의 결과보다 좋았다.
'survey' 카테고리의 다른 글
| Vision-Language Models for Vision Tasks: A Survey (1) | 2024.09.11 |
|---|---|
| A Review of Deep Learning-Based Semantic Segmentation for Point Cloud (0) | 2024.07.02 |
| Image Segmentation Using Deep Learning: A Survey (0) | 2024.06.24 |
| A Survey of Deep Learning Techniques for Autonomous Driving (0) | 2024.04.24 |