Abstract
image segmentation은 image processing과 computer vision에 주요 topic이다.
ex) scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality
Introduction
image segmention는 많은 segment나 object로 image를 분할하는 것이다.
- 과거의 image segmentation approach
1. thresholding
2. histogram-based bundling
3. region growing
4. k-means clustering
5. watersheds
6. active contours
7. graph cuts
8. conditional and Markov random field
9. sparsity based method
그러나 현재에는 deep learning model이 image segmentation model의 새로운 혁신을 만들었다.
image segmentation은 semantic label을 가지는 pixel(segmentation)이나 각 object의 분할(instance segmentation)의 classification 문제를 나타낸다.
semantic segmentation: 모든 image pixel에 대해 object category의 set를 사용해서 pixel-level labeling을 수행
instance segmentation: image에 있는 각 object의 interest를 설명과 탐지함으로써 semantic segmentation scope를 확장
- image segmentation category
1) Fully convolutional networks
2) Convolutional models with graphical models
3) Encoder-decoder based models
4) Multi-scale and pyramid network based models
5) R-CNN based models (for instance segmentation)
6) Dilated convolutional models and DeepLab family
7) Recurrent neural network based models
8) Attention-based models
9) Generative models and adversarial training
10) Convolutional models with active contour models
11) Other models
Overview of deep neural network
DL model은 새로운 application / dataset에서 처음부터 학습하지만 댑분의 경우에 label된 data가 없어서 힘들다.
-> 하나의 task에 학습된 model을 통해 얻은 초기 weight로 다른 task에 사용되는 model을 재학습하는 방법인 transfer learning을 사용
image segmentation 경우, network의 encoder part로 imagenet으로 학습된 model을 사용하고 초기 weight로 model 재학습한다.
- CNN

- CNN의 3가지 type layer
1. convolutional layer: kernel의 weight는 feature를 추출하기 위해 convolve
2. nonlinear layer: network에 non linear function의 modeling을 하기 위해, feature map에 activation function을 적용
3. pooling layer: neightborhood에 대한 통계 정보를 가지는 feature map의 작은 neighborhood를 대체하고 공간 해상도를 줄인다.
layer에 있는 unit은 지역적으로 연결됐다.
각 unit은 이전 layer의 unit의 receptive field같은 작은 neighborhood로부터 weight된 input을 받는다.
- CNN의 연산 장점
layer에 있는 receptive field는 fcn보다 상당히 작은 parameter로 weight를 공유한다.
ex) Alexnet, VGGnet, Resnet, Googlenet, Mobilenet, Densenet
- RNN, LSTM
RNN은 speech, text, video, time series와 같은 sequential data를 처리할 때 사용한다.
RNN은 long sequence일 때 long term dependency와 gradient vanishing, exploding 문제때문에 학습이 안됨

LSTM은 RNN의 문제를 보완하기 위해 design되었다.
- LSTM 구조

임의의 time interval에 값을 저장하는 memory cell로부터 정보를 들이거나 내보내는 3개의 gate
1. input gate
2. output gate
3. forget gate
- Encoder-Decoder, Auto-Encoder
Encoder-Decoder model은 two stage network를 통해 input domain에서 output domain까지 data point를 map하기 위해 학습하는 model
Encoder: latent space representation에 input을 요약
decoder: latent space representation으로부터 output을 예측
latent representation은 ouput을 예측하기 위해 사용하는 input의 semantic 정보를 처리하는 feature representation에 적용된다.
image to image translation, sequence to sequence model에 특화되어있다.
ground truth output y와 이후 reconstruction \hat y의 차이를 reconstruction loss로 최소화시킴으로써 학습됨
output은 향상된 version의 image나 segmentation map을 얻는다.
Auto-Encoder는 input과 output이 같은 특별한 경우의 encoder-decoder model이다.

- GAN

GAN은 generator와 discriminator 두가지 network로 구성되어 있다.
generator network(G)는 noise로부터 실제 sample과 비슷한 target distribution으로 mapping을 학습한다.
discriminator network(D)는 진짜로부터 생성된 sample을 구별한다.
G와 D 간 minimax game으로 GAN을 여긴다.
D는 진짜로부터 가짜 sample을 구별하는 것에 classification error를 minimize하고,
G는 discriminator network의 error를 maximize함
-> loss function을 최소화
DL-Based image segmentation model
- FCN

FCN은 image의 임의의 크기를 가지기 위해 convolutional layer만 포함하고 같은 크기의 segmentation map을 만든다.
고정되지 않은 input과 output을 만들기 위해 모든 fully convolutional layer와 fc layer 모두를 제거함으로써 기존의 VGG16과 Googlenet을 변형시켰다.
classification score 대신 공간 segmentation map을 output했다.
model의 마지막 layer에서 나온 feature map은 upsample되었고 feature map의 이전 layer를 융합한 것에 skip connection의 사용을 통해, model은 정확하고 세부적인 segmentation을 하기 위해 semantic 정보(deep, coarse layer)와 apperarance 정보(shallow, fine layer)를 결합한다.

deep network는 변동가능한 크기의 image에 end to end 방식으로 semantic segmentation에 대해 학습했다.
- FCN의 제한
1. real time에서 빠르지가 않다.
2. global context 정보를 고려하지 않는다.
3. 3D image로 변환하는 것이 쉽지 않다.
ParseNet: global context 정보를 무시하는 문제를 해결하는 model
각 위치에 있는 feature를 증가시키는 layer의 평균 feature를 사용함으로써 global context를 추가한다.

- Convolutional model with graphical model
FCN은 scene level semantic context를 무시한다.
더 많은 context를 통합하기 위해서, CRF와 MRF와 같은 확률적인 graphical model을 DL architecture에 포함한다.
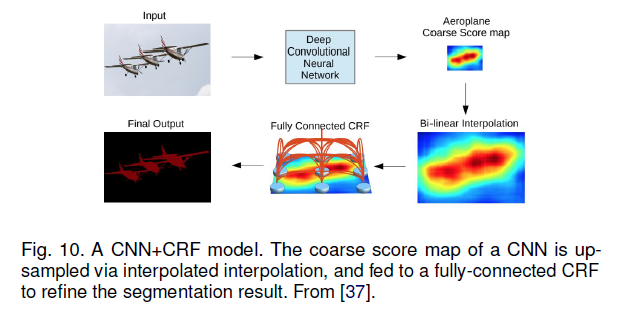
1. CNN과 fully connected CRF의 결합에 기반된 semantic segmentation을 제시
CNN의 마지막 layer에 reponse는 정확한 object segmentation에 대해 충분하지 않게 국한됐다.
deep CNN의 안 좋은 위치 속성을 극복하기 위해 fully connected CRF를 가지는 최종 CNN layer에서 response를 결합했다.
2. semantic image segmentation을 위해 CNN과 fully connected CRF를 같이 학습하는 방법 제시
3. contextual deep CRF에 기반된 semantic segmentation에 대한 효율적인 알고리즘 제시
contextual 정보의 사용을 통해 semantic segmentation을 향상시키기 위해, 'patch-patch' context와 'patch-background' context를 분석했다.
4. single forward pass에 있는 end to end 연산을 하는 Parsing network를 제시
- Encoder-Decoder based model
* for General Segmentation

Encoder: VGG16 layer network에 채택된 convolutional layer 사용
Decoder: input인 feature vector를 가지고 pixel별 class 확률의 map을 생성한다.
deconvolution network는 pixel별 class label을 확인하고 segmentation mask를 예측하는 deconvolution과 unpooling layer로 구성된다.
-- SegNet

SegNet은 image segmentation을 위해 convolutional encoder-decoder architecture 제시
deconvolution network와 비슷하게, SegNet의 핵심 학습가능한 segmentation engine은 VGG16 network에 있는 13개의 convolutional layer로 encoder network와 pixel별 classification layer로 해당 decoder network로 구성한다.
SegNet의 주요 novelty는 더 낮은 해상도 input feature map을 decoder가 upsample하는 방식이다.
non-linear upsampling을 하기 위해 해당 encoder의 max pooling step에서 계산된 pooling index를 사용한다.
up sample된 map은 dense feature map을 생성하기 위해 학습가능한 filter로 convolve된다.
Segnet은 다른 model보다 상당히 학습가능한 parameter 수가 작다.

DeConvNet, SegNet, U-Net, V-Net에서 수행되는 고해상도 representation을 복구하는 것 외에, HRNet은 병렬로 고해상도에서 저해상도 convolution stream으로 연결하고, 해상도에 정보를 반복적으로 바꿈으로써 encoding 과정을 통해 고해상도 representation을 유지한다.
semantic segmentation에서 많은 최근 work는 self attention과 extenstion처럼 contextual model을 이용함으로써 backbone으로 HRNet을 사용한다.
다른 work는 Stacked Deconvolutional Network(SDN), Linknet, W-Net, RGB-D segmentation에 대한 locality-sensitive deconvolution network로서 image segmentation에 대한 transposed convolution이나 encoder-decoder를 채택한다.
- Encoder-Decoder based model 한계
encoding 과정을 통해 고해상도 representation의 손실때문에 image의 fine grained 정보의 loss
-> 이러한 문제는 HR-Net과 같은 최신 architecture에서 해결되었음
- for Medical and Biomedical image segmentation
U-Net, V-Net은 medical domain에서 잘 알려진 두 architecture이다.
-- U-Net

segmenting biological microscopy image에 대해 U-Net을 제안
U-net의 network와 학습 전략은 매우 적게 annotate된 image로부터 학습을 위해 data augmentation의 사용에 의존한다.
U-net은 context를 포착하기 위해 contracting path와 정밀한 localization을 하게하는 대칭적인 expanding path 두 부분으로 구성되어있다.
down sampling이나 contracting part는 3x3 convolution을 가진 feature을 추출하는 FCN같은 architecture를 가진다.
upsampling이나 expanding part는 차원을 증가시키는 동안 feature map의 수를 줄이는 up convolution(deconvolution)을 사용한다.
network의 down sampling 부분으로부터 feature map은 pattern 정보를 잃는 것을 피하기 위해 up sampling part에 복사된다.
1x1 convolution은 input image의 각 pixel을 카테고리화하는 segmentation map을 생성하기 위해 feature map을 처리한다.
- U-Net의 다양한 확대
1. 3D image에 적용
2. nested U-net
3. road segmentation/ extraction 알고리즘에 사용
-- V-Net
V-Net은 3D medical image segmentation에서 FCN 기반 model로 유명하다.
model training하는 동안, foreground와 backbround에서 voxel의 수 간 심한 불균형을 해결하기 위해 Dice coefficient에 기반된 새로운 objective function을 소개한다.
medical image segmentation에서 다른 관련 work에는 Progrssive Dense V-net(PDV-Net)이 있다.
- Multi-Scale and Pyramid Network based model
image processing의 오랜 idea인 Multi-scale 분석은 다양한 neural network architecture에서 사용된다.
-- FPN
가장 유명한 model 중 하나는 Feature Pyramid Network(FPN)이다.
주로 object detection에 사용됐지만 segmentation에 적용한다.
내재된 multi-scale, deep CNN의 pyramidal hierarcy은 방대한 추가 cost로 feature pyramid를 쓰곤 했다.
저해상도와 고해상도 feature를 병합하기 위해 FPN은 bottom up pathway, top down pathway, lateral connection으로 구성되어 있다.
concatenated feature map은 각 stage의 output을 만들기 위해 3x3 convolution으로 처리된다.
top down pathway의 각 stage는 object를 detect하기 위해 prediction을 만든다.
image segmentation을 위해서, mask를 생성하는 두 개의 multi-layer perceptron(MLP)를 사용한다.

scene의 global context representation을 더 낫게 학습하는 multi-scale network인 Pyramid Scene Parsing Network(PSPN)을 제시
다른 패턴이 확장된 network와 feature extractor로서 residual network(Resnet)을 사용하는 input image로부터 추출된다.
다른 scale의 pattern을 구별하기 위해 feature map을 pyramid pooling module에 넣었다.
pyramid level에 해당하는 4개의 다른 scale로 pooling되고 차원을 줄이기 위해 1x1 convolutional layer로 처리된다.
pyramid level의 output은 upsample되고 지역과 전역 context 정보 둘 다 포착하기 위해 초기 feature map와 연결된다.
convolutional layer는 pixel별 prediction을 생성에 사용된다.
고해상도 feature map에 skip connection과 저해상도 map에 재구성된 segmentation 경계를 연속적으로 개선하기 위해 multiplicative gating을 사용하는 Laplacian pyramid에 기반된 multi-resolution reconstruction을 이용했다.
-> convolutional feature map의 공간 해상도가 낮으면 고차원 feature representation은 상당한 sub pixel localization 정보를 포함한다.
- multi-scale analysis에 사용된 segmentation model
1. DM-Net (Dynamic Multi-scale Filters Network)
2. Context contrasted network and gated multiscale aggregation(CCN)
3. Adaptive Pyramid Context Network(APC-Net)
4. Multi-scale context intertwining(MSCI)
5. salient object segmentation
- R-CNN based model(for instance segmentation)

R-CNN의 extension(Fast R-CNN, Faster R-CNN, Maksed-RCNN)은 instance segmentation 문제를 다루기 위해 많이 사용된다.
-- Mask R-CNN

object instance segmentation을 위해 Mask R-CNN 제시
Mask R-CNN은 각 instance에 대해 좋은 품질 segmentation mask를 동시에 생성하는 동안 image에서 object를 detect한다.
Mask R-CNN은 3개의 output branch를 가진 Faster R-CNN이다.
- Mask R-CNN의 3개의 ouput branch
첫번째 연산: bounding box 좌표
두번째 연산: 관련된 class
세번째 연산: object를 segment하기 위해 binary mask
Mask R-CNN loss function은 bounding box 좌표의 loss, 예측된 class, segmentation mask를 결합하고 결합한 것을 같이 학습한다.
-- PANet

Mask R-CNN과 FPN model에 기반되어있다.
network의 feature extractor는 낮은 layer feature의 progagation을 향상하기 위해 augmented bottom-up pathway를 가지는 FPN architecture를 사용한다.
3번째 pathway의 각 stage는 이전 stage의 feature map을 intput으로 간주하고 3x3 convolutional layer로 처리한다.
output은 lateral connection을 사용하는 top-down pathway의 같은 stage feature map을 추가되고 feature map은 다음 stage에 준다.
- PANet의 3개의 branch
1, 2번째: bounding box 좌표의 예측을 생성하기 위해 fc layer를 사용한다.
3번째: object mask를 predict하기 위해 FCN으로 RoI를 처리한다.
instance 미분, mask 추정, object 카테고리하는 것 3개의 network로 구성하는 instance aware semantic segmentation에 대한 multi-task network이다.
cascaded 구조로 형성되어 있고 convolutional feature를 공유하기 위해 design되었다.
새로운 가중치 전달 함수와 함께 새로운 부분 supervised training paradigm을 제안했습니다. 이 paradigm은 모두 box annotation이 있지만 그 중 극히 일부에만 mask annotation이 있는 대규모 범주 세트에서 instance segmentation model 학습을 가능하게 합니다.
-- MaskLab

Faster R-CNN에 기반된 semantic과 direction feature로 object detection을 개선함으로써 MaskLab이라는 instance segmentation model을 제시
MaskLab은 box detection, semantic segmentation, direction prediction 3가지 output으로 만들어진다.
Faster RCNN object detector 기반으로 예측된 box는 object instance의 정확한 localization을 제공한다.
각 Roi 안에서, MaskLab은 semantic과 direction prediction을 결합함으로써 foreground / background segmentation을 학습한다.
-- Tensormask
dense sliding window instance segmentation에 기반된 Tensormask 제시
dense instance segmentation을 4D tensor에 대한 예측 작업으로 처리하고 4D tensor에서 새로운 연산자를 활성화하는 일반 framework를 제시
많은 instance segmentation model은 R-CNN에 기반됐다.
ex) R-FCN, DeepMask, PolarMask, boundary-aware instance segmentation, CenterMask
bottom-up segmentation에 대한 grouping cue를 학습함으로써 instance segmentation 문제를 풀기 위해 시도한다.
ex) Deep watershed Transform, real-time instance segmentation, deep metric learning을 통한 semantic instance segmentation
- Dilated convolutional model and deeplab Family

Dilated convolution(atrous convolution)은 dilation rate라는 convolutional layer라는 다른 parameter를 도입
2 dilation rate를 가진 3x3 kernel은 9개의 parameter만 사용하면서 5x5 kernel로서 같은 크기의 receptive field를 가진다.
그러므로 연산 cost 증가 없이 receptive field를 확장한다.
Dilated convolution은 real time segmentation의 분야에서 인기있다
ex) Deeplab family, multi-scale context aggregation, dense upsampling convolution and hybrid dilatedconvolution(DUC-HDC), densely connected Atrous Spatial Pyramid Pooling(DenseASPP), efficient neural network(ENet)
-- DeepLab family
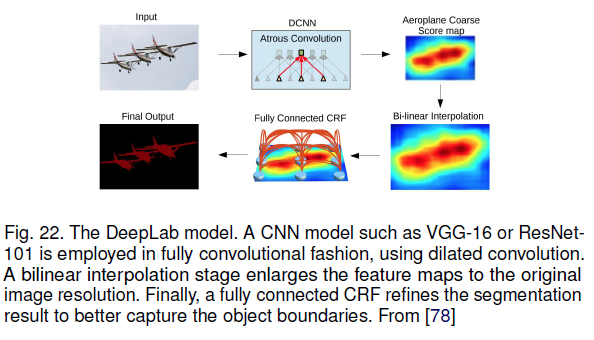
DeepLabv1, DeepLabv2는 인기있는 image segmentation 방법 중 하나이다.
- DeepLabv2의 3가지 주요 특징
1. network에서 해상도를 줄이는 것을 다루기 위해 dilated convolution의 사용
2. multiple sampling rate에서 filter로 convolutional feature layer를 탐색하는 Atrous Spatial Pyramid Pooling(ASPP)
-> multiple scale에서 image context뿐만 아니라 object를 포착하는 것은 multiple scale에서 object를 robust하게 segment한다.
3. deep CNN과 확률적인 graphical model로부터 방법을 결합함으로써 object boundary의 localization을 향상시킴

dilated convolution의 cascaded와 병렬 module을 결합하는 DeepLabv3 제시
병렬 convolution module은 ASPP에 group된다.
1x1 convolution과 batch normalisation은 ASPP에서 추가된다.
모든 output은 각 pixel에 대한 logit을 가지는 마지막 output을 만들기 위해 1x1 convolution으로 처리된다.
atrous separable convolution을 포함하는 encoder-decoder architecture을 사용하는 Deeplabv3+ 제시
Deeplabv3+는 depthwise convolution과 pointwise convolution으로 구성된다.
encoder로 DeepLabv3 framework를 사용하고 max pooling과 batch normalization 대신 더 많은 layer와 dilated depthwise separable convolution으로 변형된 xception을 사용한다.
- Recurrent Neural Network based model
RNN은 segmentation map의 추정을 향상하기 위해 pixel 사이 short/long term dependency를 modeling하는데 유용하다.
RNN을 사용하기 위해, pixel은 서로 연관되어있고 global context를 modeling하고 semantic segmentation을 향상하기 위해 처리된다.
-- Reseg
image classification에 대해 발전된 Renet에 기반된 model이다.
각 Renet layer는 방향, encoding patch/activation, 제공하는 관련 global 정보로 수평적이고 수직적으로 image를 sweep하는 4개의 RNN으로 구성되어 있다.

ReNet layer는 일반적인 local feature를 추출하는 pretrain된 VGG16 convolutional layer의 top에 쌓는다.
ReNet layer는 최종 prediction에서 기존 image 해상도를 다루기 위해 upsampling layer를 뒤있는다.
memory 사용량과 연산량 간 좋은 balance를 제공하기 때문에 GRU가 사용된다.
LSTM network에 사용해서 scene image의 pixel별 segmentation과 classification을 개발한다.
label의 복잡한 공간 dependency를 고려하는 scene의 image로 2차원 LSTM network를 연구한다.
-- Graph LSTM
일반적인 sequential data나 multidimensional data에서 graph structured data로 LSTM의 일반화하는 Graph LSTM에 기반된 semantic segmentation model 제시
존재하는 multi-dimensional LSTM 구조에서 pixel이나 patch로 image를 나누는 것 대신, 일정한 node로 임의로 shape된 superpixel을 얻고, superpixel의 공간관계는 가장자리로 사용되는 image에 대한 무방향 graph를 만든다.

전통적인 pixel별 RNN model과 graph LSTM model의 시각적 비교

semantic segmentation을 위해 Graph LSTM model을 채택하기 위해, super-pixel map에 만들어진 LSTM layer는 global structure context를 가지는 visual feature를 향상하기 위해 convolutional layer에 추가된다.
convolutional feature는 모든 label에 대한 초기 confidence map을 만들기 위해 1x1 convolutional filter를 통해 지나간다.
후속 graph LSTM를 위해 sequence를 update하는 node는 초기 confidence map에 기반된 confidence 중심의 계획으로 결정된다.
그 후, graph LSTM layer는 모든 superpixel node의 hidden state를 update한다.
-- DA-RNN
3d scene mapping과 semantic labeling에 대해 DA-RNN 제시
DA-RNN은 RGB-D video에서 semantic labeling에 대한 새로운 rnn을 사용한다.
network의 output은 reconstruct된 3D scene에 semantic information을 더하기 위해, kinect-fusion과 같은 mapping 기술과 통합된다.
image를 encode하기 위해 CNN과 natural language 설명을 encode하기 위해 LSTM을 결합해서 사용하는 nautral language expression에 기반된 semantic segmentation 알고리즘을 제시
semantic class의 미리 정의된 set에서 traditional semantic segmentation과 다릅니다.

language expression에 대한 pixel별 segmentation을 만들기 위해, 시각과 언어적 정보를 처리하기 위해 동시에 학습하는 end to end로 학습가능한 recurrent와 convolutional model을 제시
recurrent LSTM network는 vector representation에 참고 표현을 encode하는데 사용되고 FCN은 image로부터 공간 feature map을 추출하는데 사용되고 target object에 대한 공간 response map을 출력한다.
- RNN 기반 model의 한계
sequential 본성의 model때문에,
sequential 연산이 쉽게 병렬화 되지 않아서 CNN보다 더 느리다.
- Attention-based model

각 pixel 위치에 있는 multi-scale feature에 작은 가중치를 줘서 학습하는 attention 매커니즘 제시
attention 매커니즘은 average와 max pooling을 능가하고 다른 position과 scale에 있는 feature의 중요성을 평가하기 위해 modeling한다.

-- RAN
reverse attention 매커니즘을 사용하는 semantic segmentation 방법 제시
RAN arcitecture는 반대 개념(target class와 연관없는 feature)을 포착하기 위해 model을 학습한다.
RAN은 direct와 reverse attention learning 과정을 동시에 수행하는 3개의 branch network다.
-- PAN
semantic segmentation에 대한 Pyramid Attention Network 제시
PAN은 global contextual 정보의 영향을 이용한다.
복잡한 dilated convolution과 인공적으로 design된 decoder network 대신 pixel labeling에 대한 정밀한 dense feature를 추출하기 위해 attention 매커니즘과 공간 pyramid를 결합한다.
self attention 매커니즘에 기반된 풍부한 contextual dependency를 포착하기 위해 scene segmentation에 대한 dual attention network를 제시
공간과 channel 차원에 semantic 상호 의존성을 modeling하는 dilated FCN의 top에서 attention module의 두가지 type을 추가한다.
position attention module은 모든 position에서 feature의 weight된 합으로써 각 position에서 feature를 선택적으로 합한다.
- 다양한 attention 매커니즘 model
1. OCNet: self attention 매커니즘에서 영감받은 object context pooling 제시
2. EMANet
3. CCNet
4. recurrent attetion로 end to end instance segmentation
5. scene parsing에 대한 point별 spatial attention network
6. DFN: 두 sub network인 smooth network와 Border network로 구성
- Generative model and adversarial training

semantic segmentation에 대한 adversarial training 방법 제시
segmentation network에 의해 생성된 것으로부터 ground truth segmentation map을 구별하는 adversarial network와 함께 convolutional semantic segmentation network를 학습
GAN을 사용하는 semi weakly supervised semantic segmentation을 제시
K개의 possible class로부터 label y에 sample을 할당하거나 fake sample로 표시하는 GAN framework에서 discriminator로 역할을 맡는 multi-class classifier로 extra training example을 제공하는 generator network로 구성된다.
adversarial network를 사용하는 semi supervised semantic segmentation에 대한 framework 제시
공간 해상도를 고려하는 ground truth segmentation distribution으로부터 예측된 확률 map을 구별하기 위해 FCN discriminator를 design한다.
- model의 3가지 loss function
1. segmentation ground truth에서 cross-entropy loss
2. discriminator network의 adversarial loss
3. confidence map에 기반된 semi supervised loss
medical image segmentation에 대해 multi-scale L1 loss로 adversarial network를 제시
segmentation label map을 생성하기 위해 segmentor로서 FCN을 사용하고 critic에 집중하는 multi-scale L1 loss function과 pixel 간 길고 짧은 범위 공간 관계를 포착하는 global, local feature 둘다 학습하는 segmentor를 가진 새로운 adversarial critic network를 제시
- CNN model with active contour model
한가지 방법은 ACM 원칙으로 영감되는 새로운 loss function을 만든다.
예측된 mask의 영역과 크기 정보를 포함하고 cardiac MRI에 있는 ventricle segmentation의 문제를 다루는 supervised loss layer를 제시
다른 방법은 FCN의 output의 후처리로서 초기에 ACM을 활용하는 것을 추구하고 FCN을 pretraining함으로써 같이 학습하는 것을 시도한다.
medical image segmentation에 대해 새롭고 locally parameter화된 level set engergy function의 parameter function을 예측하기위해 FCN backbone을 학습하는 통합된 DALS model을 제시
공중 image에 있는 building instance segmentation에 대한 예측 framework에서 ACM과 pretrain된 FCN를 결합하는 Deep Structured Active Contours(DASAC)를 제시
- Other model
- Context Encoding Network(EncNet)
-> 기본 feature extractor을 사용하고 Context Encoding module에 feature map을 준다
- RefineNet
-> long range residual connection을 사용해서 고해상도 예측을 하게하는 down sampling 과정에 따라 사용가능한 모든 정보를 이용하는 multi-path refinement network이다.
- Seednet
-> interactive segmentation 문제를 풀기 위해 학습하는 deep reinforcement learning을 가지는 자동 seed generation 기술이다.
- OCR
ground truth의 supervision에 object region을 학습하고, object region representation, 각 pixel과 각 object region 간 관계 를 계산하고, OCR로 representation pixel을 늘린다.
- 추가 model
- BoxSup
- Grapth convolutional network
- Wide Resnet, Exfuse
- Feedforward-net
- geodesic video segmentation에 대한 saliency aware model
- DIS
- FoveaNet
- BiseNet
- SPGNet
- Gated shape CNN
- AC-net
- DSSPN
- SGR
- CascadeNet
- SAC
- Upernet
- 재학습과 self training으로 segmentation
- densely connect된 neural architecture search
- hierarchical multi-scale attention
Panoptic segmentation은 인기가 많아지고 있는 segmentation 문제이다.
- Panoptic segmentation model
- Panoptic FPN
- panoptic segmentation에 대한 attention guided network
- seamless scene segmentation
- panoptic deeplab
- unified panoptic segmentation network
- 효율적인 panoptic segmentation
Image Segmentation Dataset
medical domain과 같이 작은 dataset을 대처하기 위해 label된 sample의 수를 늘리기 위해 data augmention을 이용한다.
- 2D dataset
1.PASCAL VOC
2. PASCAL Context
3. MS COCO
4. Cityscape
5. SceneParse150
6. SiftFlow
7. Stanford background
8. BSD
9. Youtube-Object
10. KITTI
- other dataset
SBD, PASCAL Part, STNTHIA, Adobe's Portrait segmentaiton
- 2.5D dataset
range scanner를 활용한 RGB-D image dataset은 연구와 산업에서 인기이다.
1. NYU-D V2
2. SUN-3D
3. SUN RGB-D
4. UW RGB-D Object dataset
5. Scannet
- 3D dataset
3D image dataeset은 robotic, mdical image 분석, 3D scene 분석, 건설 분야에서 인기이다.
3차원 image는 point cloud같은 mesh나 다른 volumetric representation을 통해 제공된다.
1. Stanford 2D-3D
2. ShapeNet Core
3. Sydnet Urban Object dataset
Performance review
- Metrics for segmentation model
1. Pixel accuracy
전체 pixel 수로 나눠지는 적절하게 분류된 pixel의 비율

2. Mean Pixel Accuracy(MPA)
올바른 pixel의 비율이 class별 방식으로 연산되고 전체 class 수로 평균낸다.

3. IoU or Jaccard Index
Semantic segmentation에서 가장 일반적으로 사용되는 metrics
예측된 segmentation map과 ground truth 간 교집합이 합집합에 의해 나눠진다.

4. Mean-IoU
모든 class로 IoU를 평균냄
현재 segmentation 알고리즘의 성능 평가로 사용됨
5. Precision / Recall / F1 score
고전적인 image segmentation의 정확도를 평가하는 유명한 metrics
Precision, recall은 aggregate level뿐만 아니라 각 class에 대한 정의

F1 score는 precision과 recall의 조화평균

6. Dice coefficient
예측되고 ground truth map의 overlap area는 image에 있는 전체 pixel 수로 나눠진다.


Dice coefficient는 F1 score와 동일하다
Challenge and Opportunity
큰 scale image dataset은 sematntic segmentation과 instance segmentation을 위해 만들어졌음
그러나, image의 경우 여전히 object의 많은 수와 overlapping object을 가지는 dataset은 귀중하다.
training model은 현실에서 일반적인 object 간 큰 overlap뿐만 아니라 dense object scene을 다루기 쉽다.
3D iamge segmentation은 더 낮은 차원 dataset보다 만들기 더 어렵다.
그래서 3D image dataset은 매우 귀중하다.
- Weakly Supervised and unsupervised learning
Weakly supervised(few shot learning)과 unsupervised learning은 활발한 연구 분야다.
segmentation 문제에 대한 label된 sample을 모으는것이 어려워서 가치 있는 기술이다.
transfer learning 방법은 label된 sample의 큰 set으로 일반적인 image segmentation model로 학습하는 것이다.
구체적인 target 적용으로부터 적은 sample으로 model을 finetune한다.
self supervised learning은 다른 유망한 방향이다.
self supervised learning의 도움으로 더 적은 training sample로 segmentation model을 학습하는 것을 포착하는 image에 많은 세부사항이 있다.
MOREL: video에서 동적 object segementation을 위해 reinforcement learning을 사용
- Real-time model for various application
거의 실시간으로 또는 적어도 거의 일반적인 카메라 프레임 속도로 실행할 수 있는 segmentation model을 가지는 것은 중요하다.
현재 model의 대부분은 autonomous vehicle의 프레임 속도와 거리가 멀다.
-> FCN-8은 저해상도 image를 처리하기 위해 100ms 걸린다.
dilated convolution에 기반된 model은 segmentation model의 속도를 증가시키기 위해 도움을 주지만 약간의 향상을 준다.
- Memory efficient model
현대 segmentation model은 inference 단계동안 상당한 memory량이 필요하다.
mobile phone같이 특정 device에 맞추기 위해. network는 간단해야한다.
더 간단한 model을 사용하는 것이나 compression 기술을 사용하는 것이나 복잡한 model을 학습한 후 지식 증류 기술을 사용하여 복잡한 모델을 모방하는 더 작고 메모리 효율적인 네트워크로 압축함으로써 수행할 수 있습니다.
- 3D point cloud segmentation
3D modeling, self driving car, robotic, building modeling 등 다양한 application을 가지는 point cloud segmentation에 관심도가 증가하고 있다.
point cloud와 같이 순서없고 비정형인 3D data를 처리하는 것은 몇가지 어려움이 있다.
CNN과 다른 고전적인 deep learning architecture를 적용하는 가장 좋은 방법은 분명하지 않다.
graph에 기반된 deep model은 point cloud segmentation에 대한 잠재력이 있다.
'survey' 카테고리의 다른 글
| Vision-Language Models for Vision Tasks: A Survey (1) | 2024.09.11 |
|---|---|
| A Review of Deep Learning-Based Semantic Segmentation for Point Cloud (0) | 2024.07.02 |
| A Survey of Deep Learning Techniques for Autonomous Driving (0) | 2024.04.24 |
| A survey: object detection methodsfrom CNN to transformer (0) | 2024.03.28 |