Abstract
이 논문은 object detection에 대한 convolutional network 방법(fast r-cnn)에 기반된 fast region을 제안한다.
fast r-cnn은 deep convolutional network를 사용하는 object proposal을 분류하기 위해 효율적으로 이전 작업에서 만들었다.
이전 작업과 비교해서 fast r-cnn은 detection 정확도를 높이는 동시에 학습과 테스트 속도를 향상시키는 여러가지 혁신이 쓰인다.
fast r-cnn은 r-cnn보다 9배 더 빠른 매우 깊은 vgg16 network를 학습하고, test time에는 213배 더 빠르며 pascal voc 2012에서 더 높은 mAP를 달성한다.
SPPnet과 비교하면, fast r-cnn은 3배 더 빠른 vgg16을 학습하고 10배 더 빨리 테스트되며 더 정확하다.
Introduction
최근에 deep convnet은 image classification과 object detection 정확도를 상당히 향상시켰다.
image classification과 비교할 때, object detection은 해결하기 위해 더 복잡한 방법을 필요로 하는 어려운 task이다.
복잡성때문에 현재 방법들은 multi stage pipeline에서 느리고 매력적이지 못한 model을 학습한다.
detection은 object의 정확한 localization이 필요하고 두가지 주요 과제때문에 복잡성이 생긴다.
- detection의 두가지 주요 과제
- 많은 후보의 object location이 처리되어야함
- 많은 후보들은 정확한 localization을 달성하기 위해 개선되는 대략적인 localization을 제공한다.
논문에서 우리는 object detector에 기반된 sota convnet에 대한 학습 과정을 간소화한다.
우리는 object proposal을 분류하는 것을 학습하는 single stage 학습 알고리즘을 제안하고 공간적인 위치를 개선한다.
방법의 결과는 r-cnn보다 9배 더 빠르고 SPPnet보다 3배 더 빠른 매우 깊은 detection network를 학습할 수 있다.
실행시간에, detection network는 0.3s마다 image를 처리하며 pascal voc 2012에서 66%의 mAP로 최고의 정확도를 찍는다.
* R-CNN and SPPnet
convolutional network 방법에 기반된 region은 object proposal을 분류하기 위해 깊은 convnet을 사용함으로써 훌륭한 object detection 정확도를 달성한다.
- r-cnn의 중요한 결점 세가지
1. 학습은 multi stage pipeline이다
r-cnn은 먼저 log loss를 사용하여 object proposal에 대한 fine tuning한다.
그 후, svm에서 convnet feature에 맞추고 이 svm은 fine tuning으로 softmax classifier를 대체하는 object detector로서 역할을 한다.
3번째 학습 stage에서 bounding box regressor는 학습되어졌다.
2. 학습은 공간과 시간이 많이 든다.
svm과 bounding box regressor 학습에 대한 feature는 각 image의 각 object proposal에서 추출되어 disk에 기록된다.
vgg16과 같은 매우 깊은 network로 이 과정은 voc07 trainval set의 5k개의 image에 대해 GPU로 2.5일 소요된다.
이 feature는 수백 기가바이트의 용량이 필요하다
3.object detection은 느리다
테스트할 때, feature는 각 test image에서 각 object proposal로부터 추출되어졌다.
vgg16을 사용한 detection은 image당 47s 걸린다.
r-cnn은 공유 연산없이 각 object proposal에 대해 convnet forward pass를 하기 때문에 느리다.
Spatial pyramid pooling network(sppnet)은 연산을 공유함으로써 r-cnn의 속도를 높이는 것을 제안한다.
sppnet 방법은 전체 input image에 대해 convolutional feature map을 연산하고 공유된 feature map으로부터 추출된 feature vector를 사용하는 각 object proposal을 분류한다.
feature는 고정된 size의 output으로 proposal에 있는 feature map의 부분을 max pooling함으로써 proposal에 대해 추출되어졌다.
multiple output 사이즈는 pooling되어졌고 그 후 spatial pyramid pooling에 연결되어졌다.
sppnet은 test 시간에 10배에서 100배로 r-cnn을 가속화한다.
학습 시간은 더 빠른 proposal feature 추출때문에 3배 더 감소했다.
sppnet은 중요한 결점을 가진다.
r-cnn과 같은 학습은 feature를 추출하고 log loss를 가진 network를 fine tuning하고 svm을 학습하고, bounding box regressor를 맞추는 것을 포함하는 multi stage pipeline이다.
하지만 r-cnn과 달리 fine tuning 알고리즘은 spatial pyramid pooling을 앞서는 convolutional layer를 업데이트하지 않는다.
놀랍지 않게도, 이 제한은 매우 깊은 network의 정확도를 제한한다.
* Contributions
r-cnn과 sppnet의 약점을 고친 network의 속도와 정확도를 향상시키는 새로운 학습 알고리즘을 제안한다.(fast r-cnn)
- fast r-cnn 방법의 몇가지 장점
- r-cnn, sppnet보다 더 높은 detection 품질(mAP)
- 학습은 multi task loss를 사용하는 single stage이다
- 학습은 모든 network layer를 업데이트한다
- disk 용량이 없는 것은 feature caching이 필요하다
Fast R-CNN architecture and training

fast r-cnn network는 전체 image와 object proposal의 set을 input으로 간주한다.
network는 conv feature map을 만들기 위해 몇몇 convolutional(cov)와 max pooling layer로 전체 image를 먼저 처리한다.
그 후 각 object proposal에 대한 region of interest(ROI) pooling layer는 feature map으로부터 고정된 길이의 feature vector를 추출한다.
각 feature vector는 최종적으로 두 개의 sibling output layer로 분기되는 일련의 fc layer에 입력된다.
k개의 object class에 대한 softmax 확률 추정을 만드는 것은 각각 k개의 object class에 대한 4개의 실수 값을 출력하는 다른 layer와 포괄적인 "background" class를 더한다.
각 4개의 value set은 K개의 class중 하나에 대해 개선된 bounding box 위치를 encode한다.
* The RoI pooling layer
ROI pooling layer는 H와 W가 독립된 특정한 roi인 layer hyper parameter로 고정된 공간적인 extent인 H x W가 있는 작은 feature map으로 유효한 roi 안에 있는 feature를 바꾸기 위해 max pooling을 사용한다.
이 논문에서, roi는 cov feature map에 있는 직사각형 window이다.
각 roi는 top-left corner(r,c)와 roi의 height와 width(h,w)를 명시하는 four-tuple(r,c,h,w)에 의해 정의되어졌다.
roi max pooling은 대략적인 크기인 h/H x w/W sub-window를 H x W grid로 나눈 다음
각 sub window의 값을 해당 출력 grid cell에 max pooling하는 방식으로 작동한다.
pooling은 기존 max pooling의 경우와 같이 각 feature map channel에 독립적으로 적용되어졌다.
roi layer는 하나의 피리미드 레벨만 있는 sppnet에 사용된 공간적인 pyramid pooling layer의 특별한 경우이다.
* Initializing from pre-trained networks
우리는 5개의 max pooling layer와 5개에서 13개 사이의 conv layer를 가진 imagenet에 pretrain된 세가지 network로 실험한다.
- pretrain된 network가 fast r-cnn network를 초기화했을 때
- 마지막 max pooling layer는 H와 W가 network의 첫번째 fc layer와 호환되도록 구성된 ROI pooling layer로 대체됨
- network의 마지막 fc layer와 softmax는 앞에서 설명한 비슷한 두개의 layer로 대체됨
- network는 두 가지 데이터 입력인 image list외 해당 image의 ROI list를 사용하도록 수정됨
* Fine-tuning for detection
역전파로 모든 network 가중치를 학습하는 것은 fast r-cnn의 중요한 특성이다.
- 왜 sppnet이 공간적인 pyramid pooling layer 아래에서 가중치를 업데이트 할 수 없는지
$\rightarrow $ 근본 원인은 각 훈련 샘플이 다른 이미지에서 나올 때 SPP 계층을 통한 역전파가 매우 비효율적이라는 것입니다.
이것이 바로 R CNN 및 SPPnet 네트워크가 훈련되는 방식입니다.
비효율성은 각 roi가 전체 input image에 걸쳐 매우 큰 receptive field를 가질 수 있다는 사실에서 유래된다.
순전파는 전체 receptive field를 거쳐야하므로 학습 input이 크다.
우리는 학습하는 동안 공유 feature를 이용하는 더 효율적인 방법을 제안한다.
fast r-cnn 학습에서 sgd mini batch는 먼저 N개의 image를 샘플링하고, 다음 각 image에서 R/N개의 roi를 샘플링해서 계층적으로 샘플링된다.
비평적으로, 같은 image에서 roi는 순전파와 역전파에서 연산과 메모리를 공유한다.
N을 작게 만들면 mini batch 연산이 감소한다.
예를 들면, N=2, R=128일 때, proposed 학습 방법은 128개의 다른 image에서 하나의 roi를 샘플링하는 것보다 64배 더 빠르다.
이 전략에서 하나의 개념은 같은 image로부터 roi가 맞춰지기 때문에 학습 수렴이 느릴지도 모른다.
이 개념에서 우리는 현실적으로 문제가 되지 않는 것으로 보이고 r-cnn보다 더 적은 SGD iteration을 사용해서
좋은 결과가 나왔다.
계층적인 샘플링뿐만 아니라 fast r-cnn은 세 개의 분리 stage에서 softmax classifier, svm과 regressor를 학습하는 것보다 합동으로 softmax classifier와 bounding box regressor를 최적화하는 하나의 fine tuning stage로 간소화된 학습 과정을 사용한다.
- Multi-task loss
fast r-cnn network는 두개의 sibling output layer가 있다.
첫번째 layer는 K+1개의 카테고리에 별개의 확률 분포인 $ p=(p_0,.....p_k) $를 출력한다.
보통 p는 fc layer의 k+1개의 output에서 softmax에 의해 계산되어진다.
두번째 sibling layer는 k에 의해 index된 각각의 k개의 object class에 대한 bounding box regression의 위치좌표 $ t^k = (t_x^k,t_y^k,t_w^k,t_h^k) $을 출력한다.
t^k는 object proposal에 대한 scale invariant translation과 log space height/width 이동을 지정한다.
각 학습 ROI는 ground truth class u와 ground truth bounding box regression target v로 label되어있다.
우리는 classification과 bounding box regression에 대한 학습을 위해 각 라벨된 ROI에서 multi task loss L을 사용한다.
$L_{cls}(p, u)$ = $-logp_u$가 진짜 class u에 대해 log loss이다.
두번째 task loss인 $L_{loc}$은 class $u, v = (v_x,v_y,v_w,v_h)$와 예측된 tuple $t^u= (t_x^u,t_y^u,t_w^u,t_h^u)$에 대해 진짜 bounding box regression target의 tuple에서 정의되어졌다.
iverson bracket indicator function은 u>=1일 때 1로 평가되고 그렇지 않으면 0으로 평가된다.
관례적으로 포괄적인 background class는 u = 0으로 표시된다.
background ROI에 대해 ground truth bounding box의 개념이 없다.
그러므로 $L_{loc}$은 무시되어진다.
bounding box regression에 대해 우리는 r-cnn과 sppnet에 사용되는 L2 loss보다 outlier에 덜 감각적인 robust L1 loss를 사용한다.
regression target이 무한한 경우 L2 loss로 학습하는 것은 exploding gradient를 막기 위해 learning rate의 조정을 조심할 필요가 있다.


방정식 3은 민감도를 제거한다.

방정식 1에 있는 하이퍼 파라미터 람다는 두 task loss 사이에서 균형을 제어한다.
우리는 평균과 단위분산을 0으로 가지기 위해 ground truth regression target $v_i$를 일반화한다.
모든 실험은 람다= 1을 사용한다.
우리는 class agnostic object proposal을 학습하기 위해 관련된 loss를 사용하는 것을 주목한다.
우리의 접근법과 달리, localization과 classification을 분리하는 두 개의 network 시스템에 대해 옹호한다.
overfeat, r-cnn, sppnet은 classifier과 bounding box localizer를 학습한다.
그러나 이 방법은 우리가 fast r-cnn에 대해 최적이 아닌 stage별 학습을 사용한다.
- Mini-batch sampling
fine tuning하는 동안, 각 SGD mini batch는 random에서 획일적으로 선택된 N이 2인 image로 구성되어있다.
우리는 각 image로부터 64개 ROI를 샘플링하는 R이 128인 크기의 mini batch를 사용한다.
우리는 최소 0.5인 ground truth bounding box와 IOU가 겹치는 object proposal에서 ROI의 25퍼를 가져온다.
이 roi는 foreground object class(u>=1)로 라벨된 예를 구성한다.
남아있는 ROI는 [0.1,0.5) 사이에서 ground truth로 maximum IOU를 가지는 object proposal로부터 샘플되어진다.
남아있는 ROI는 background 예제이고, u = 0으로 라벨되어있습니다.
0.1의 낮은 threshold는 hard example mining에 대해 경험적 방법으로 작용하는 것으로 보인다.
학습하는 동안, image는 수평적으로 0.5 확률을 가지고 뒤집는다.
다른 data augmentation은 사용하지 않았다.
- Back-propagation through ROI pooling layers
역전파는 roi pooling layer를 통해 미분을 라우팅한다.
명확성을 위해, 우리는 순전파가 독립적으로 모든 image를 다루기때문에 N>1로 확장은 간단하지만 mini batch당 하나의 image만(N=1) 추정한다.
$x_i$ ∈R은 ROI pooling layer에서 i번째 활성화 input이 되고, $y_{rj}$는 r번째 roi로부터 j번째 output이 된다.
roi pooling layer는 output unit인 $y_{rj}$가 max pool하는 sub window에서 h i*(r,j) = argmax_{i∈R(r,j)}x_i R(r, j)는 index set에 있는 yrj = xi *(r,j)를 계산합니다
단일 $x_i$는 몇가지 다른 output인 $y_{rj}$를 할당할지도 모른다.
roi pooling layer의 backwards 함수는 argmax 전환따라서 각 input 변수 $x_i$에 관해서 부분미분의 loss function을 계산한다.

말로는, 각 mini batch ROI r과 각 pooling output unit y_{rj}에 대해 부분적인 미분은 만약 i가 max pooling에 의해 y_rj에 대해 선택되어진 argmax라면 축적되어진다.
역전파에서 부분 미분은 roi pooling layer의 가장 위에 있는 layer의 backward 함수에 의해 이미 계산되어졌다.
- SGD hyper-parameters
softmax classification과 bounding box regression을 위해 사용된 fc layer는 각각 표준편차 0.01과 0.001로 평균이 0인 가우시안 분포로부터 초기화되어졌다.
bias는 0으로 초기화되어진다.
모든 layer는 가중치가 1, bias가 2인 layer별 learning rate와 0.001의 global learning rate를 사용합니다.
VOC07이나 VOC12 trainval에서 학습할 때, 우리는 30k mini batch iteration으로 SGD를 돌리고 그 후 learning rate를 0.0001로 더 줄이고 다른 10k iteration으로 학습한다.
우리가 더 큰 dataset으로 학습할 때, 우리는 더 많은 iteration으로 SGD를 돌린다.
0.9 momentum과 0.0005 파라미터 decay를 사용했다.
* Scale invariance
- scale invariant object detection을 하는 두가지 방법
- 브루트 포스 학습
- image pyramid 사용
브루트 포스 방법에서 각 image는 학습과 테스트 둘 다 하는 동안 미리 정의된 pixel 크기로 처리되어진다.
network는 학습 데이터로부터 scale invariant object detection을 똑바로 학습해야한다.
대조적으로, multi scale 방법은 image pyramid를 통한 network로 거의 정확한 scale invariance를 제공한다.
테스트에서, image pyramid는 각 object proposal을 거의 정확한 scale로 정규화하기 위해 사용한다.
multi scale 학습하는 동안 우리는 data augmentation의 형태로 image가 샘플링될 때 마다 무작위로 pyramid 크기를 샘플링한다.
우리는 gpu memory 제한때문에 더 작은 network로 multi scale 학습을 실험한다.
Fast R-CNN detection
fast r-cnn network는 fine tuning되어지며 detection은 순전파로 실행하는 것보다 약간 더 많다.
network는 점수를 매길 image와 R개의 object proposal의 list를 입력으로 사용한다.
테스트에서 R이 약 2000개지만 우리는 더 많은 경우를 고려할 것이다.
image pyramid를 사용할 때, 각 roi는 스케일링된 roi가 영역에서 224 pixel에 가까운 scale로 할당되어진다.
각 test roi r에 대해, 순전파는 class의 사후 확률 분포 p와 r과 관련해서 예측된 bounding box 좌표의 set을 출력한다.
우리는 추정된 확률 pr ∆= pk를 사용해서 각 object class k에 대한 r에 detecton confidence를 할당한다.
우리는 r-cnn으로부터 설정과 알고리즘을 사용하는 각 class에 대해 관계없이 nms를 한다.
* Truncated SVD for faster detection
전체 image classification에 대해 fc layer를 계산하는데 쓴 시간은 conv layer와 비교해서 매우 적다.
그와 반대로 roi의 수를 detection하기 위해 처리하는 것은 오래 걸리고 순전파 시간의 절반 정도가 fc layer를 계산하는데 쓰인다.
많은 fc layer는 truncated SVD로 압축함으로써 쉽게 가속화된다.

이 기술에서, u x v weight matrix에 의해 파라미터화된 layer W는 SVD를 사용해서 대략 인수분해된다.
- U: W의 첫번째 t개의 왼쪽 특이 벡터를 포함하는 u x t 행렬
- Σt: W의 상위 t개의 특이값을 포함하는 t x t 대각행렬
- V: W의 첫번째 t개의 오른쪽 특이 벡터를 포함하는 v x t 행렬
truncated SVD는 만약 t가 min(u,v)보다 훨씬 더 작다면 중요할 수 있는 uv로부터 t(u+v)까지 파라미터 개수를 줄인다.
network를 압축하기 위해, w에 해당하는 단일 fc layer는 비선형없이 두개의 fc layer에 의해 대체되어졌다.
이 layer의 첫번째는 weight matrix ΣtVT를 사용하고 두번째는 U를 사용한다.
간단한 압축 방법은 roi의 수가 많을 때 빠른 스피드를 가진다.
Main results
- 논문에 기여하는 세가지 주요 결과
- voc07, voc2010과 2012에서 sota mAP가 나옴
- R-CNN, SPPnet과 비교해서 빠른 학습과 테스트
- VGG16에서 fine tuning conv layer는 mAP를 향상한다.
* Experimental setup
- online에 사용가능한 pretrain된 imagenet 모델 3개
- r-cnn에서 caffenet(model S)
- VGG_CNN_M_1024(model M)
- VGG16(model L)
이 section에서의 모든 실험은 single scale 학습과 테스트를 사용한다.
* VOC 2010 and 2012 results


이 dataset에서 우리는 fast r-cnn을 공개한 리더보드의 comp4 트랙에 있는 상위방법과 비교한다.
nus_nun_c2000과 baby learning 방법의 경우 현재 관련된 출판물이 없고 사용된 convnet architecture에 대한 정확한 정보를 찾을 수 없다.
이는 network in network 디자인의 변형이다.
전체 다른 방법은 같은 pretrain된 VGG16 network로부터 초기화되어진다.
fast r-cnn은 voc12에서 65.7% mAP로 가장 좋은 결과를 달성한다.
느린 r-cnn pipeline에 모두 기반된 다른 방법보다 2배 더 빠르다
voc10에서 segDeepM은 fast r-cnn보다 더 높은 mAP를 달성한다.
segDeepM은 voc12 trainval + segmentation annotation에 대해 학습되어진다.
O2P sementic segmentation 방법에서부터 r-cnn detection과 segmentation에서 markov random field를 사용함으로써 r-cnn 정확도를 증가시키기 위해 고안되어졌다
fast r-cnn은 더 나은 결과로 이끌지도 모르는 r-cnn을 대신해서 segDeepM으로 바꿔질 수 있다.
확장된 07++12 training set을 사용할 때, fast r-cnn의 mAP가 segDeepM을 능가하는 68.8%로 증가한다.
* VOC 2007 results
voc07에서, 우리는 fast r-cnn을 R-CNN, SPPnet과 비교한다.
모든 방법은 같은 pretrain된 VGG16 network로부터 시작하고 bounding box regression을 사용한다.
SPPnet은 학습과 테스트 둘 다 5개의 scale을 사용한다.
SPPnet에 비해 fast r-cnn의 향상은 fast r-cnn이 single scale 학습과 테스트를 사용하는 것에도 불구하고 fine tuning한 conv layer는 mAP에서 큰 향상이 되는 것을 묘사한다.
r-cnn은 66.0% mAP를 달성한다
사소한 문제로서, SPPnet은 pascal에 어려움으로 표시된 예제없이 학습되어졌다.
이 예제를 없애는 것은 fast r-cnn mAP를 68.1%로 향상한다.
모든 다른 실험은 어려운 예제를 사용한다.
* Training and testing time

위 표는 voc07에서 fast r-cnn, r-cnn, sppnet 간에 학습시간(시간), 테스트율(이미지당 초), mAP를 비교한다.
vgg16에서 fast r-cnn은 truncated SVD없이 r-cnn보다 146배 더 빠르게 image를 처리하고 truncated SVD가 있으면 213배 더 빠르다.
학습 시간은 84시간에서 9.5시간으로 9배 더 줄였다.
sppnet과 비교해서 fast r-cnn은 vgg16을 2.7배 더 빠르게 학습하고 truncated SVD없이 7배 더 빠르거나 truncated SVD있이 10배 더 빠르게 테스트한다.
feature를 캐시에 저장할 수 없기 때문에 fast r-cnn은 수백개의 gigabyte의 disk 용량을 제거한다.
- Truncated SVD
truncated SVD는 mAP를 작은 감소와 model 압축 후에 추가적인 fine tuning을 수행하기 위해 필요한 것 없이 detection 시간을 30%보다 더 많이 줄였다.

위 그림은 VGG16의 fc6 layer에 있는 25088 x 4096 matrix로부터 1024개의 특이값과 4096 x 4096 fc7 layer로부터 256개의 특징값을 사용해서 mAP에 있는 작은 loss로 runtime을 어떻게 줄이는지를 묘사한다.
게다가, 만약 압축 후에 fine tuning을 다시 한다면 속도 높이는 것은 더 작은 감소로 가능하다.
* Which layers to fine-tune?
sppnet 논문에서 고려된 적은 deep network의 경우, fine tuning한 fc layer는 충분히 높은 정확도로 나타났다.
우리는 이 결과가 매우 깊은 network에 대해 유지하지 않는다는 것을 가설했다.
fine tuning한 conv layer는 vgg에 대해 중요하다는 것을 유효하기 위해, 우리는 fine tuning하기 위해 fast r-cnn을 사용하지만 fc layer가 학습하기 위해 13개의 conv layer를 동결한다.

single scale sppnet 학습을 모방하고 66.9%에서 61.4%로 mAP가 줄었다.
roi pooling layer를 통한 학습은 매우 깊은 network에 중요하다는 우리의 가설을 입증한다.
Q. 모든 conv layer가 fine tuning되어야 하는가?
A. NO
더 작은 network에서, 우리는 conv1이 포괄적이고 독립된 task라는 것을 알았다.
conv1에 학습을 하거나 안 하거나를 허용하는 것은 mAP에 의미있는 효과를 가지지않는다.
VGG16의 경우, 우리는 conv3_1이상의 layer만 업데이트하는 것이 필수적인 것을 알았다.
- conv2_1로부터 업데이트하는 것은 conv3_1로부터 학습하는 것과 비교해서 1.3배 학습이 느리다.
- conv1_1로부터 업데이트하는 것은 GPU memory를 초과한다.
conv2_1이상으로 학습할 때, mAP에서 차이는 0.3%뿐이었다.
모든 fast r-cnn은 conv3_1이상의 VGG16 fine tuning layer를 사용하는 논문에서 모델 S와 M의 fine tuning된 conv2이상의 layer를 가진 모든 실험결과를 낸다.
Design evaluation
* Does multi-task training help?
순차적으로 학습된 task의 pipeline을 관리하는 것을 피하기 때문에 multi task training은 편리하다.
그러나 task는 공유된 representation을 통해 서로 영향을 미치기 때문에 multi task training은 결과를 향상하는 잠재력을 가지고 있다.
- multi task 학습은 fast r-cnn에서 object detection 정확도를 향상시키나요?

1. classification loss L_{cl}s만 사용하는 baseline network를 학습한다.
이 model은 bounding box regressor을 가지지 않는다.
2. 모든 세가지 network에서 우리는 multi task training이 classification만 학습하는 것에 관련된 순수 classification 정확도를 향상하는 것을 관찰했다.
향상 범위는 multi task learning으로부터 일관된 긍정적인 효과를 보이는 +0.8에서 +1.1 mAP 점수이다.
3. baseline model을 가지고 bounding box regression layer를 덧붙이고 동결된 전체 다른 network 파라미터를 유지하는 동안 L_{loc}로 학습한다.
mAP는 첫번째 열에 비해 향상되었지만 단계별 학습은 multi task training의 기량만큼 발휘 못한다.
* Scale invariance: to brute force or finesse?
- scale invariant object detection을 하기 위한 두가지 전략 비교
- brute force 학습(single scale)
- image pyramid(multi scale)
어느쪽이든 우리는 image의 scale s를 가장 짧은 변의 길이로 정의한다.
전체 single scale 실험은 600 픽셀(s)을 사용한다.
s는 우리가 1000 픽셀로 가장 긴 image 변을 한도로 정하고 image의 종횡비를 유지함으로써 몇개의 image에 대해서는 600보다 낮을 지도 모른다.
이 값은 VGG16이 fine tuning하는 동안 GPU memory에 맞추기 위해서 선택되어졌다.
더 작은 model은 memory bound가 없고, 더 큰 값의 s로부터 유용할 수 있다.
그러나 각 model에 대해 최적화하는 것은 주요 염려가 아니다.
우리는 pascal image가 평균인 384 x 473 픽셀이고 그러므로 single scale 설정은 일반적으로 image를 1.6배로 upsample한다.
roi pooling layer에서 효과적인 평균 stride는 약 10pixel이다.
multi scale 설정에서, 우리는 SPPnet과 비교 가능하게 같은 5개의 scale을 사용한다.
그러나 우리는 GPU memory를 초과하는 것을 피하기 위해 2000 pixel로 가장 긴 변을 한도로 정한다.

하나나 5개의 scale 어느 하나로 학습하거나 테스트할 때, 위 표는 model S와 M을 보여준다.
가장 놀라운 결과는 single scale detection은 multi scale detection과 마찬가지로 성능을 낸다.
deep convnet은 즉시 scale invariance를 학습하는 것이 채택되어졌다.
multi scale 방법은 계산시간이 많이 소요되지만 mAP는 약간 증가한다.
VGG16의 경우에서, 우리는 실행 세부사항으로 single scale을 사용하는 것을 제한한다.
r-cnn은 각 proposal이 표준 size에 휘어지는 느낌으로 infinite scale을 사용함에도 불구하고, r-cnn에 대해 보고된 66.0%보다 약간 더 높은 66.9%의 mAP로 약간 증가한다.
특히 매우 깊은 model에서 single scale 과정은 속도와 정확도 간 가장 좋은 tradeoff를 제공하기 때문에 sub section 밖에 있는 모든 실험은 600 픽셀로 single scale 학습과 테스트를 사용한다.
* Do we need more training data?
더 많은 학습 데이터와 같이 공급되었을 때 좋은 object detector는 향상되야한다.
zhu et al은 DPM의 mAP가 수백번에서 천 번의 학습 예제 후에 포화된다는 것을 알았다.
우리는 fast r-cnn을 평가하기 위해 voc07 trainval set을 voc12 trainval set으로 증강해서 대략 3배 정도의 16.5k의 image 수로 늘린다.
학습 set을 확장하는 것은 voc07 test에서 mAP를 66.9%부터 70.0%까지 향상한다.
- 학습 설정
- 60k minibatch iteration을 사용한다.
- voc10 및 2012에 대해 유사한 실험을 수행하여 voc07 trainval, test 및 voc12 trainval 통합에서 21.5k image의 데이터 셋
- 100k SGD iteration을 사용하고 각 40k iteration의 learning rate를 0.1배 낮췄다
voc10과 2012에 대해, mAP는 66.1%에서 68.8%와 65.7%에서 68.4%로 각각 향상한다.
* Do SVMs outperform softmax?
fast r-cnn은 r-cnn과 sppnet에서 된 것처럼 사후에 one vs rest linear svms를 학습하는 것 대신에 fine tuning하는 동안 학습한 softmax classifier를 사용한다.
이 선택의 영향을 이해하기 위해서, 우리는 fast r-cnn에서 hard negative mining으로 사후 svm 학습을 시행했다.
r-cnn에서 같은 학습 알고리즘과 하이퍼파라미터를 사용한다.
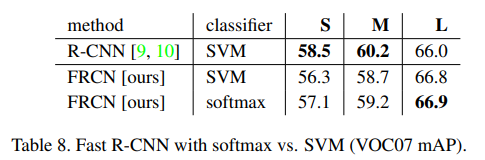
위 표는 mAP 점수가 +0.1에서 +0.8로써 전체 세 개의 network로 svm을 약간 능가하는 softmax를 보여준다.
이 효과는 작지만 one shot fine tuning은 비교된 이전의 multi stage 학습 방법에 충분한 것을 입증한다.
one vs rest SVMs과 달리 softmax는 roi를 점수낼 때 class 간에 경쟁을 하는 것을 주목한다.
* Are more proposals always better?
- object detector의 두가지 타입
- object proposal의 sparse set을 사용하는 것
- dense set을 사용하는 것
sparse proposal을 분류하는 것은 proposal 매커니즘이 먼저 수많은 후보를 거부하고 classifier를 평가할 작은 set으로 남겨두는 cascade 유형이다.
이 cascade는 DPM detection을 적용했을 때, detection 정확도를 향상시킨다.
selective search의 품질 모드를 사용할 때, 우리는 model M을 재학습하고 재테스트하는 시간에 image당 1k에서 10k proposal을 sweep한다.
만약 proposal이 계산 역할만 하는 경우, image당 proposal의 수가 증가하는 것은 mAP에 해를 주지 않아야 한다.

proposal 개수가 증가할 때, 우리는 mAP가 증가하고 약간 떨어지는 것을 알았다.
이 실험은 더 많은 proposal을 가진 깊은 classifier를 swamping하는 것은 도움을 주지 않고 정확도를 약간 감소시키는 것을 보여준다.
object proposal 품질을 측정하는 것에 대한 sota는 AR이다.
AR은 image당 고정된 많은 proposal을 사용할 때 r-cnn을 사용해서 많은 proposal 방법에 대한 mAP와 상관관계가 좋다.
위 그림은 image당 proposal 수가 다른 것만큼 AR이 mAP와 상관관계가 좋지 않다는 것을 보여줘서 AR는 주의해서 사용해야 한다.
더 많은 proposal로 인해 AR이 높아진다고 해서 mAP가 증가한다는 의미는 아니다.
model M으로 학습과 테스트하는 것은 2.5시간보다 덜 걸린다.
따라서 fast r-cnn은 proxy metrics보다 선호되는 object proposal mAP를 효율적이고 직접적으로 평가할 수 있다.
우리는 image당 약 45k box의 비율로 dense하게 생성된 box를 사용할 때 fast r-cnn을 연구한다.
각 selective search box가 가장 가까이 있는 dense box로 대체될 때 이 dense set은 mAP가 1퍼만 떨어질만큼 충분히 많다.
2k selective search box부터 시작해서, 우리는 1000 x {2,4,6,8,10,32,45} dense box의 무작위 샘플을 추가할 때, mAP를 테스트한다.
각 실험에서 우리는 model M을 재학습하고 재테스트한다.
dense box가 더해졌을 때, selective search box를 더했을때보다 mAP는 53.0%에 가깝게 많이 떨어졌다.
우리는 dense한 box들만 사용해서 fast r-cnn을 학습하고 테스트해서 52.9%의 mAP를 냈다.
마지막으로, 만약 hard negative mining으로 svm이 dense box 분포에 대처하기 위해 필요하다면 우리가 체크한다.
svm은 49.3%로 훨씬 안 좋다.
* Preliminary MS COCO results
예비 baseline을 설정하기 위해 MS COCO dataset에 fast r-cnn을 적용했다.
평가 sever를 사용하는 test-dev set에서 평가하고 240k iteration에 대한 80k image training set을 학습했다.
pascal 스타일 mAP는 35.9%, IOU threshold를 초과하는 평균인 새로운 coco 스타일 mAP는 19.7%이다.
Conclusion
이 논문은 r-cnn과 sppnet에 대해 깔끔하고 빠른 업데이트를 하는 fast r-cnn을 제안한다.
sota detection 결과를 보고할 뿐 아니라 우리는 우리가 새로운 통찰력을 제공할 수 있는 세부적인 실험을 제시한다.
특히 주목할 점은, sparse object proposal이 detector 품질을 향상시키는 것으로 보인다.
이 주제는 과거에 너무 비싸서 조사하지 못했지만 fast r-cnn을 사용하면 실현가능하다.
물론, dense한 box들이 sparse proposal뿐만 아니라 성능을 발휘할 수 있도록 하는 아직 발견되지 않은 기술이 존재할 수도 있다.
만약 이런 방법이 개발되었다면 object detection을 가속화하는데 도울지도 모른다.