Abstract
detection을 하기 위해 classifier를 고치는 것 대신에 우리는 분리된 bounding box와 연관된 class 확률에 regression 문제로서 object detection frame을 설정한다.
single neural network는 한 번의 평가에서 full image로부터 bounding box와 class 확률을 예측한다.
전체 detection pipeline은 single network때문에 detection 구현에서 end to end로 최적화될 수 있다.
우리의 base yolo model은 실시간에서 초당 45 frame으로 image를 처리한다.
network의 더 작은 version인 fast yolo는 다른 실시간 detector의 mAP에 두배인 반면에 믿기 어려운 초당 155 frame을 처리한다.
sota detection system과 비교할 때, yolo는 더 많은 localization error를 만들지만 background에서 false positive를 예측하는 것은 덜하다
마침내, yolo는 object의 일반적인 representation을 학습한다.
artwork같은 다른 domain에서 natural image로부터 일반화할 때, yolo는 DPM과 R-CNN을 포함하는 다른 detection 방법을 능가한다.
Introduction
인간은 image를 보고 image에 어떤 object가 있는지, 어디에 있는지, 어떻게 상호작용하는지 즉시 알 수 있다.
human visual system은 빠르고 정확하므로 의식적인 생각이 거의 없이 운전과 같은 복잡한 작업을 수행할 수 있습니다.
object detection를 위한 빠르고 정확한 알고리즘을 통해 컴퓨터는 특수 센서 없이 자동차를 운전할 수 있고, 보조 장치가 실시간 장면 정보를 human user에게 전달할 수 있으며, 범용 반응형 로봇 시스템의 잠재력을 발휘할 수 있습니다.
object를 detection하기 위해 detection system은 object에 대한 classifier를 취하고, 다양한 location에서 평가하고 test image의 크기를 조정한다.
우리는 image pixel에서 bounding box 좌표와 class 확률까지 object detection을 single regression 문제로 다시 구성한다.
우리의 시스템을 사용하면, 우리는 무슨 object가 존재하는지 어디에 있는지 예측하는 것을 image에서 yolo로 한다.

yolo는 간단하다.
single convolutional network는 많은 bounding box와 box에 대한 class 확률을 동시에 예측한다.
yolo는 전체 image로 학습하고, detection 성능을 즉시 최적화한다.
- 통합된 model의 이점
- yolo는 극심하게 빠르다.
regression 문제로서 detection을 frame하기 때문에 복잡한 pipeline이 필요하지 않는다.
우리의 base network는 titan x gpu에서 batch 과정 없이 초당 45 frame으로 돌리고 fast version은 150 fps이상으로 실행됩니다 -> 25ms의 latency보다 적은 실시간에서 video를 streaming하는 것을 처리할 수 있다는 것이다.
yolo는 다른 실시간 시스템의 mean average precision(mAP)보다 두 배 더 많았다. - yolo는 예측할 때 image에 대해 전역적으로 추론한다.
sliding window와 region proposal에 기반된 기술과 달리, yolo는 training과 test time 동안에 전체 image를 본다.
그래서 구조뿐만 아니라 class에 대한 context 관련 정보를 함축적으로 encode한다.
yolo는 fast r-cnn에 비해 background error의 수가 절반 미만이다. - yolo는 object의 일반화할 수 있는 representation을 학습한다.
natural image로 학습할 때와 artwork로 test할 때, yolo는 wide margin으로써 DPM과 r-cnn과 같은 가장 좋은 detection 방법을 능가한다.
yolo는 매우 일반화할 수 있기 떄문에 new domain이나 예상치못한 input을 적용할 때, 실패하는 것이 적다.
yolo는 sota detection system보다 정확도가 뒤떨어져있다.
image에서 object를 빨리 식별할 수 있는 반면에, 특히 작은 몇몇 object를 정밀하게 localize하는 것은 고군분투한다
Unified Detection
우리는 single neural network에서 object detection의 개별 요소를 통합한다.
우리의 network는 각 bounding box를 예측하기 위해 전체 image로부터 feature를 사용하고, image에 대한 모든 class에 걸쳐 모든 bounding box를 동시에 예측한다.
-> network가 전체 image와 image에 있는 모든 object에 대해 전역적으로 추론한다는 뜻이다.
yolo는 end to end training을 하고 높은 average precision(AP)를 유지하는 동안에 실시간 speed를 높인다.

우리의 시스템은 S x S grid에 넣어서 input image를 나눈다.
만약에 object의 중심이 grid cell로 들어가면, grid cell은 object를 detect하는 역할을 한다.
각 grid cell은 B개의 bounding box와 각 box에 대한 confidence score를 예측한다.

confidence score: box에 object가 포함되어 있는지 얼마나 확신하는지와 box가 예측한 것이 얼마나 정확한지를 나타내는 것
confidence = Pr(Object)*IOU
만약에 object가 cell에서 존재하지 않는다면 confidence score는 0이 되야하고, 그렇지 않으면 우리가 예측한 box와 ground truth 간에 confidence score와 IOU가 동등하길 원한다.
각 bounding box는 5개의 prediction (x,y,w,h,confidence)으로 구성한다.
(x,y) 좌표: grid cell의 경계를 기준으로 box의 중심
width와 height는 전체 image를 기준으로 예측됐다.
confidence prediction은 예측된 box와 ground truth box 간에 IOU를 나타낸다.
각 grid cell은 조건부 class 확률 (Pr(Class_i|Object)) 을 예측한다.
이 확률은 object를 포함하는 grid cell에서 결정된다.
우리는 B box의 수와 상관없이 grid cell당 class 확률의 한 set을 예측한다.
test때 우리는 각 box에 대한 class별 confidence score를 주는 조건부 class 확률과 개별 box confidence 예측을 곱한다.
score: box에 나타나는 class의 확률과 예측된 box가 object를 얼마나 잘 맞게 됐는지를 encode한다.
* Network Design

fc layer는 output 확률과 좌표를 예측하는 동안 network의 첫 convolutional layer는 image로부터 feature를 추출한다.
network: 2개의 fc layer 뒤에 24개의 convolution layer로 구성
googlenet에 의해 사용된 inception module 대신에, 우리는 3x3 convolutional layer 뒤에 1x1 reduction layer를 사용한다.
우리는 빠른 object detection의 경계를 넘도록 설계된 yolo의 빠른 verision을 학습한다.
fast yolo는 더 적은 convolutional layer와 이 layer에서 더 적은 filter를 가지고 neural network를 사용한다.
network의 크기 외에 모든 training과 testing parameter는 yolo와 fast yolo가 비슷하다.
network의 마지막 output은 7x7x30 prediction tensor이다.
* Training
우리는 pretraining을 위해 average pooling layer와 fc layer 뒤에 20개의 convolutional layer를 사용한다.
#우리는 대략 한 주에 network를 학습하고 imagenet 2012 validation set에서 88%의 top5 정확도를 single crop에서 달성한다.
우리는 모든 training과 inference를 위해 darknet framework를 사용한다.
pretrain된 network에 convolutional과 connected layer 둘 다 추가하는 것은 성능을 향상시킬 수 있다.
우리는 4개의 convolution layer와 무작위로 초기화된 weight를 가진 두개의 fc layer를 추가한다.
detection은 fine grain된 visual information이 필요하다.
그래서 224x224에서 448x448로 network의 input 해상도를 올린다.
우리의 마지막 layer는 class 확률과 bounding box 좌표 둘 다 예측한다.
우리는 image width와 height에 의해 bounding box width와 height를 일반화한다
bounding box x와 y 좌표를 특정 grid cell 위치의 offset으로 parameter화하여 0과 1 사이로 경계를 지정합니다.

우리는 마지막 layer에 linear activation function을 사용하고 다른 모든 layer는 leaky rectified linear activation를 사용한다.
우리는 최적화하기 쉽기때문에 우리의 model의 output에 sum squared error(sse)로 최적화한다.
그러나 우리의 AP를 최대화하는 목표와 완벽하게 일치하지 않아서 이상적이지 않는 classification error와 같은 localization error에 동등하게 가중치를 준다.
또한, 모든 image에 있는 많은 grid cell은 object를 포함하지 않는다.
cell의 confidence score이 0으로 수렴하는 것은 object를 포함하는 cell로부터 gradient를 압도한다.
일찍 발산하는 training때문에 model 불안정으로 이끈다.
불안정을 해결하기 위해, 우리는 bounding box 좌표 예측으로부터 loss를 증가시키고 object를 포함하지 않는 box에 대한 confidence prediction으로부터 loss를 줄인다.
sse는 큰 box와 작은 box에 동등하게 weight error를 준다.
우리의 error metric은 큰 box에서 작은 편차가 작은 box보다 덜 중요하다.
특정하게 다루기 위해 우리는 width와 height 대신에 bounding box width와 height의 제곱근을 예측한다.
yolo는 grid cell당 많은 bounding box를 예측한다.
training time에 우리는 object에 대해 하나의 bounding box predictor만 담당하기를 원한다.
우리는 예측이 ground truth를 통해 가장 높은 현재 IOU를 가지는데 기반된 object를 예측하는데 담당하는 하나의 predictor를 할당한다.
각 predictor는 특정 size, 종횡비나 object의 class를 더 잘 예측하는 것과 전반적인 recall을 향상시키는 것에서 더 나았다.
training하는 동안 우리는 multi part loss function 다음을 최적화한다.

1_i^obj: object가 cell i에서 나타난다면 정의
1_ij^obj: cell i에서 j번쨰 bounding box predictor는 rediction을 담당하는 것을 정의
object가 grid cell에 있으면 loss function은 classification error만 패널티를 부과한다.
predictor가 ground truth box에 책임이 있으면 bounding box 좌표 error에 패널티를 부과한다.
data: pascal voc 2007과 2012 training과 validation data
epoch:135
batch size: 64
optimizer: 0.9 momentum
weight decay: 0.0005
learning rate schedule: 첫 epoch에서 10^-3에서 10^-2로 느리게 증가시킴.
우리가 높은 learning rate로 시작한다면 불안정한 기울기때문에 우리의 model이 발산한다.
우리는 75 epoch동안 10^-2, 그 후 30 epoch동안 10^-3, 마지막으로 30 epoch동안 10^-4로 학습한다.
overfitting을 피하기 위해 dropout과 대규모의 data augmentation을 사용한다.
첫 connected layer 후에 0.5 dropout layer는 layer 간에 상호작용을 막는다.
data augmentation를 위해 우리는 원래 image 크기의 20%로 무작위 scaling하고 변형을 도입한다.
우리는 HSV color space에서 image의 채도와 노출을 1.5배까지 무작위로 조정한다.
* Inference
yolo는 classifier에 기반된 방법과 달리 single network 평가만 필요하므로 test time에 극심하게 빠르다.
grid design은 bounding box prediction에서 공간 다양성을 적용한다.
종종 object가 어느 grid cell에 속하는지 분명하고 network는 각 object에 대해 하나의 box만 예측한다.
그러나 몇몇 큰 object나 많은 cell의 경계 근처에 있는 object는 많은 cell로 잘 localize될 수 있다.
r-cnn이나 dpm 경우처럼 성능에 중요하지 않지만, non maximal suppression(NMS) 는 mAP에서 2~3%를 좋아진다.
* Limitations of YOLO
각 grid cell은 두개의 box만 예측하고 하나의 class만 가지므로 bounding box prediction에서 강한 공간 제약을 부과한다.
이러한 공간적 제약으로 인해 모델이 예측할 수 있는 인근 객체의 수가 제한됩니다.
우리의 model은 새 때같이 group에 나타나는 작은 object에 고군분투한다.
model은 data로부터 bounding box를 예측하기 위해 학습하기 때문에 새롭거나 일반적이지 않은 종횡비나 배열에 있는
object를 일반화하기 어렵다.
우리의 model은 구조가 input image로부터 많은 downsampling layer를 가지므로 bounding box를 예측하기 위해
상대적으로 coarse feature를 사용한다.
마침내, 우리는 detection 성능에 근접한 loss function을 학습하는 동안, 우리의 loss function은 큰 bounding box에 비해 작은 bounding box에서도 동일하게 error를 처리한다.
큰 box에서 작은 error는 일반적으로 양성이지만 small box에서 작은 error는 IOU에 더 많은 영향을 준다.
error의 주요 원천은 부정확한 localization이다.
Comparison to Other Detection Systems
- detection pipeline 작동 순서
- input image로부터 robust feature의 set을 추출(일반적인 시작)
- classifier나 localizer는 feature space에서 object를 확인하는데 사용
- classifier나 localizer는 전체 image 또는 image에서 region의 subset에서 sliding window 방식으로 실행
- deformable parts models
deformable parts model은 object detection에 sliding window 접근법을 사용한다.
DPM은 고정적인 feature을 추출하는 것, region을 분류하는 것, 높은 점수인 region에 bounding box 예측 등을 하기 위해
분리된 pipeline을 사용한다.
우리의 system은 single cnn에 있는 다른 부분의 모든 것을 대체한다.
network는 feature extraction, bounding box prediction, non maximal suppression과 동시에 모든 맥락추론을 수행한다.
고정적인 feature 대신에, network는 line 안에 있는 feature를 학습하고 detection task에서 최적화한다.
- R-CNN
r-cnn과 r-cnn의 변형은 image에서 object를 찾기위해 sliding window 대신에 region proposal을 사용한다.
selective search는 잠재적인 bounding box를 생성하고, convolutional network는 feature를 추출하고 svm은 box를 점수내고 linear model은 bounding box를 조절한다.
그리고 NMS는 복제된 detection을 제거한다.
복잡한 pipeline의 각 stage는 독립하여 정밀하게 조절되어야하고 resulting system은 test에서 image당 40초보다 많이 걸리므로 매우 느리다.
- yolo와 r-cnn의 공통점
- 각 grid cell은 잠재적인 bounding box를 제안
- convolutional feature를 사용한 box를 점수낸다.
- yolo와 r-cnn의 차이점
- 같은 object의 많은 detection을 줄이는 것을 돕는 grid cell proposal에 공간 제약조건을 넣는다.
- selective search로부터 image당 98개로 더 적은 bouding box를 제안
마침내 우리의 system은 최적화된 model인 single로 개인적인 구성 요소를 결합한다.
- Other Fast Detectors
fast와 faster r-cnn은 연산 공유와 selective search 대신에 region을 제안하는 neural network를 사용함으로써 r-cnn framework를 속도 올리는 것에 집중한다.
r-cnn을 넘는 속도와 정확도 향상을 제공하는 반면에 둘 다 실시간 성능은 별로다.
많은 연구는 DPM pipeline에 속도를 올리는데 집중하는데 노력한다.
그리고 HOG 연산 속도를 올렸고 cascade를 사용하고 gpu에 연산을 넣는다.
그러나 30hz DPM만 실시간에서 작동한다.
더 큰 detection pipeline의 개인적인 요소를 최적화하기 위해 시도하는 것 대신에 yolo는 pipeline을 완전히 없애고 빠르다.
많은 연구들은 훨씬 적은 분산을 다루므로 얼굴이나 사람같이 single class에 대한 detector는 아주 최적화될 수 있다.
yolo는 동시에 다양한 object를 detect하기 위해 학습하는 detector가 목적이다.
- Deep Multibox
multibox는 single class prediction으로 confidence prediction을 대체함으로써 single object detection을 학습할 수 있다.
그러나, multibox는 일반적으로 object detection을 학습할 수 없고 image patch 분류가 더 필요한 더 큰 detection pipeline 일부분이다.
yolo와 multibox 둘 다 image에서 bounding box를 예측하기 위해 convolutional network를 사용하지만 yolo는 완벽한 detection system이다.
- Overfeat
overfeat은 sliding window dertection을 효과적으로 수행한지만 여전히 분리된 시스템이다.
그리고 detection 성능이 아닌 localization에 대해 최적화한다.
dpm같이 localizer는 예측할 떄 local 정보만 본다.
overfeat은 global 맥락에 대해 추론할 수 없다.
그러므로 일관성있는 detection을 만들기 위해 중요한 전처리가 필수이다.
- MultiGrasp
bounding box prediction에 대한 우리의 grid 방법은 grasps을 regression하기 위해 multigrasp system에서 기반되어졌다.
그러나 grasp detection은 object detection보다 훨씬 간단한 task이다
multigrasp는 한개의 object를 포함하는 image에 대해 single graspable region을 예측할 필요가 있다.
object의 크기, 위치, 경계를 추정하거나 class를 예측할 필요가 없으며, grasping에 적합한 영역만 찾습니다.
yolo는 image에 있는 많은 class의 많은 object에 대한 bounding box와 class 확률 둘 다 예측한다.
Experiments
pascal voc 2007에서 다른 real time detection system과 yolo를 비교한다.
yolo와 r-cnn의 변종 간에 차이를 이해하기 위해, yolo와 fast r-cnn로 만들어진 voc 2007에 있는 error를 분석한다.
다양한 error 개요에 기반해서 우리는 yolo가 fast r-cnn detection을 재점수낼 수 있고 상당한 성능을 증가시키는
background false positive로부터 error를 줄인다는 것을 나타낸다.
우리는 voc 2012 결과를 나타내고 현재 sota 방법에서 mAP를 비교한다.
마침내, 우리는 yolo가 두개의 artwork dataset에서 다른 detector보다 더 나은 새로운 domain을 일반화하는 것을 보여준다.
* Comparison to other real time system
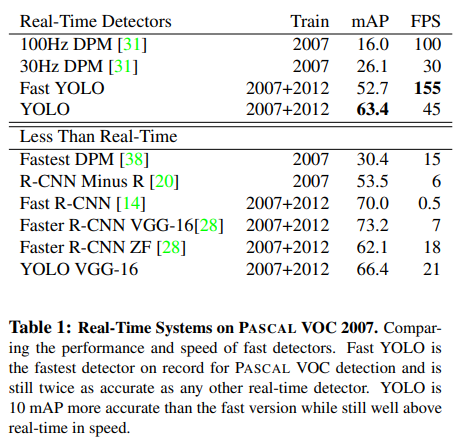
30hz 또는 100hz 중 하나를 실행하는 DPM의 GPU 구현과 yolo를 비교한다.
다른 것은 real time 단계에 도달하지 못하지만 상대 mAP와 속도를 비교하여 object detection system에서 사용할 수 있는 정확도 성능 tradeoff을 검토합니다.
fast yolo는 pascal에서 가장 빠른 object detection 방법이다.
52.7% mAP인 fast yolo는 real time detection에서 이전 것보다 두배 더 정확하다.
real time 성능을 여전히 유지하는 반면에 yolo는 63.4%로 mAP를 올렸다.
우리는 vgg16을 사용해서 yolo를 학습한다.
이 model은 더 정교하지만 yolo보다 상당히 느리다.
vgg16에 의존하는 다른 detection system와 비교하는 것이 유용하지만 더 빠른 model에 집중하는 나머지 논문에 있는 realtime보다 더 느리다.
더 빠른 DPM은 높은 mAP에 희생없이 DPM을 효과적으로 속도를 올렸다.
하지만 여전히 real time 성능이 2배나 부족하다.
neural network 접근법에 비교해서 detection에서 상대적으로 DPM의 낮은 정확도로 제한되어졌다.
R-cnn minus R은 고정적인 bounding box proposal을 가진 selective search를 대체한다.
R-cnn보다 훨씬 더 빠른 반면에, 여전히 실시간에 적용하기에 부족하고 좋은 proposal을 가지지 않는것으로부터 정확도가 크게 저하된다.
fast r-cnn은 r-cnn의 분류 단계를 속도를 높인다.
하지만 bounding box proposal을 생성하기 위해 image당 2초걸리는 selective search에 의존한다.
그러므로 높은 mAP를 가지지만 0.5 fps로 real time에 적용하기에는 여전히 멀다.
최근 faster r-cnn은 bounding box를 제안하기 위해 neural network로 selective search를 대체한다.
test에서 더 작고 덜 정교한 것이 18 fps로 작동하는 동안 가장 정확한 model은 7 fps를 달성한다.
faster r-cnn의 vgg16 버전은 10 mAP가 더 높지만 yolo보다 6배 더 느리다.
zeiler fergus의 faster r-cnn은 yolo보다 2.5배 더 느리지만 덜 정교하다.
* Voc 2007 error analysis
yolo와 sota detector 간에 차이를 조사하기 위해 우리는 voc 2007에서 세부적인 실패의 결과를 본다.
우리는 fast r-cnn이 pascal에서 가장 높은 성능을 보이는 detector 중 하나이므로 yolo와 fast r-cnn을 비교하고
detection은 공개적으로 이용가능하다.

test time에서 우리는 category를 대한 top N개의 prediction을 본다.
각 prediction은 정확하거나 error 유형에 따라 분류된다.
• Correct: correct class and IOU > .5
• Localization: correct class, .1 < IOU < .5
• Similar: class is similar, IOU > .1
• Other: class is wrong, IOU > .1
• Background: IOU < .1 for any object
yolo는 올바르게 object를 localizer하는데 고군분투한다.
localization error는 결합된 모든 다른 source보다 yolo의 error가 더 많다고 설명한다.
fast r-cnn은 훨씬 더 적은 locallization error를 가지지만 더 많은 background error를 가진다.
top detection의 13.6%는 object를 포함하지 않는 false positive다.
fast r-cnn은 yolo보다 background detection을 예측할 가능성이 거의 3배 더 높습니다.
* Combining Fast R-CNN and Yolo
yolo는 fast r-cnn보다 훨씬 더 적은 background 실수를 한다.
yolo는 fast r-cnn으로부터 background detection을 제거하기 위해 yolo를 사용함으로써 성능을 상당히 끌어올렸다.
r-cnn이 예측하는 모든 bounding box에 대해 만약 yolo가 비슷한 box를 예측한다면 yolo에 의해 예측된 확률과 두 box 간 겹치는 것에 기반된 예측에 향상을 제공한다.

최고의 fast r-cnn model은 voc 2007 test set에서 71.8%의 mAP를 달성한다.
yolo를 결합했을 때 mAP가 3.2%에서 75.0%까지 올랐다.
우리는 fast r-cnn의 몇몇 다른 버전과 같이 top fast r-cnn을 결합하는 것을 시도했다.
ensemble은 mAP에서 0.3에서 0.6% 정도로 작은 증가를 보였다.
YOLO의 향상은 Fast R CNN의 다양한 버전을 결합해도 이점이 거의 없기 때문에 단순히 모델 앙상블의 부산물이 아니다.
오히려, YOLO가 테스트할 때 다양한 종류의 실수를 하기 때문에 Fast R-CNN 성능을 향상시키는 데 매우 효과적입니다.
불행하게도, 우리가 각 model을 돌리고 결과를 결합하므로 이 결합은 yolo의 속도로부터 이점이 없다.
그러나 yolo는 너무 빨라서 fast r-cnn에 비해 계산 시간이 크게 추가되지 않는다.
* VOC 2012 Results

voc 2012 test set에서, yolo는 57.9% mAP를 달성한다.
이것은 vgg16을 사용한 original r-cnn에 가까운 현재 sota보다 더 작다.
우리의 system은 가장 가까운 competitor에 비해 작은 object에 고군분투한다.
bottle, sheep, tv/monitor같은 카테고리에서 yolo는 r-cnn이나 feature edit보다 8~10% 더 낮다.
그러나, cat과 train같은 다른 카테고리에서 yolo는 더 높은 성능을 보인다.
fast r-cnn+yolo가 결합된 model은 가장 높은 성능을 보이는 detection 방법 중 하나이다.
fast r-cnn은 yolo와 결합으로부터 2.3% 향상된다.
* Generalizability: person detection in artwork
object detection에 대한 학문적인 dataset은 같은 분포에 있는 training과 tesing data를 가져온다.
실제 응용 프로그램에서 가능한 모든 case를 사용해서 예측하는 것은 어렵고 test data는 system이 이전에 봤던 것에서 나뉠 수 있다.
우리는 picasso dataset과 people art dataset에서 다른 detection system과 yolo를 비교한다
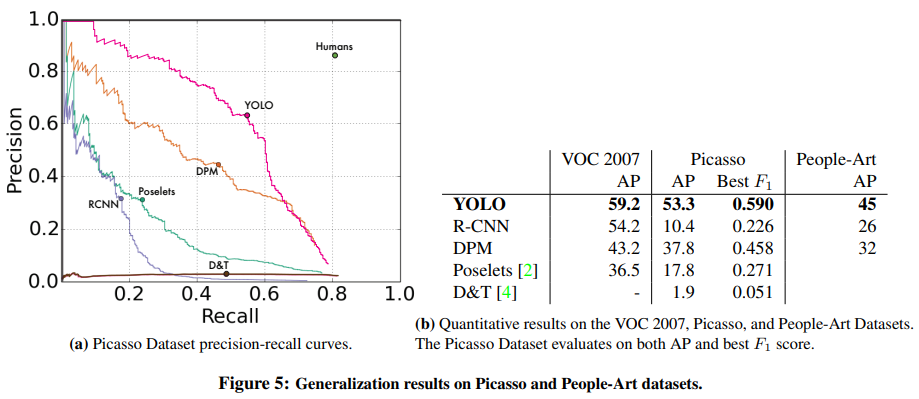
r-cnn은 voc 2007에서 높은 AP를 가진다.
그러나 r-cnn은 artwork에 적용했을때 상당히 떨어졌다.
r-cnn은 natural image에 대해 조정되는 bounding box proposal에 selective search를 사용한다.
r-cnn에서 classifier 단계는 작은 region들만 보고 좋은 proposal을 필요로 한다.
DPM은 artwork에 적용할 때 AP를 잘 유지한다.
이전 work는 강력한 공간적인 model과 object의 배치를 가졌기 때문에 DPM이 성능이 좋았다는 것을 이론을 제시한다.
DPM은 R-CNN만큼 저하시키지않지만, 더 낮은 AP에서 시작한다.
yolo는 voc 2007에서 좋은 성능을 가지고 AP는 artwork에 적용시킬때 다른 방법보다 덜 저하된다.
DPM같이 yolo는 object와 object가 일반적으로 어디에서 나타나는지 간 관계뿐만 아니라 object의 크기와 모양을 모델링한다.
artwork와 natural image는 pixel 수준에서 매우 다르지만 그들은 object의 크기와 모양에 관해 비슷하다.
그러므로 yolo는 좋은 bouding box와 detection을 여전히 예측할 수 있다.
Real-Time Detection in the wild

yolo는 빠르고 정교한 object detector다
우리는 webcam에 yolo를 연결시키고 카메라에서 image를 가지고 오는 시간을 포함하는 real time 성능을 유지하는데 입증하고 detection을 보여준다.
결과 system은 상호적용적이고 매력적이다.
yolo는 개별적으로 image를 처리하는 반면에 webcam에 연결하면 tracking system처럼 작동해서 object가 움직이고 모양이 변할 때 감지한다.
Conclusion
우리는 object detection에 대해 통합된 model인 yolo를 소개한다.
우리의 model은 간단하고 전체 image를 즉시 학습할 수 있다.
classifier에 기반된 방법과 달리, yolo는 detection 성능에 해당하는 loss function을 학습하고 전체 model은 같이 학습됐다.
fast yolo는 가장 빠른 일반적인 object detector이고 yolo는 real time object detection에서 sota이다.
yolo는 빠르고 견고한 object detection에 의존하는 application에 대한 이상적인 새로운 domain에 잘 일반화된다.
'computer vision > object detection' 카테고리의 다른 글
| SSD: Single Shot MultiBox Detector (1) | 2024.02.08 |
|---|---|
| YOLO9000: Better, Faster, Stronger (1) | 2024.01.15 |
| Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (0) | 2023.09.20 |
| Fast R-CNN (0) | 2023.09.20 |
| Rich feature hierarchies for accurate object detection and semantic segmentation (0) | 2023.07.13 |