Abstract
만약 input에 가까운 layer와 output에 가까운 layer 간에 더 짧은 connection을 포함한다면 cnn은 학습하는데 더 깊고 정확하고 효율적이라고 최근 연구에서 나타났다.
feed-forward 방식에서 다른 모든 layer에서 각 layer를 연결하는 Densenet을 소개한다.
L layer가 있는 기존의 cnn은 각 layer와 이후 layer 사이에 하나씩 L개의 connection을 가지는 반면에, network는 L(L+1)/2개의 직접적인 connection이 있다.
각 layer에 대해 모든 이전 layer의 feature map이 input으로 사용되며, 자체 feature map은 모든 후속 레이어에 대한 input으로 사용됩니다.
- Densenet의 advantage
1. vanishing gradient 문제 완화
2. feature propagation 강화
3. feature 재사용 권장
4. parameter의 수를 줄인다.
우리는 매우 경쟁력있는 object recognition benchmark task(CIFAR-10, CIFAR-100, SVHN, Imagenet)에서 제안된 architecture를 평가한다.
Densenet은 더 적은 연산으로 sota를 넘어서 상당한 향상이 되었다.
Introduction
CNN은 visual object recognition에 대한 dominant machine learning 방법이 된다.
20년 전에 소개됐음에도 불구하고, computer hardware와 network 구조에서 향상은 최근에 deep CNN의 학습을 하게한다.
기존 Lenet5는 5개 layer로 구성되고, VGG는 19개, 작년 Highway network와 Residual network(Resnet)은 100개 layer를 능가한다.
CNN이 점점 깊이가 증가하므로 network의 끝에 도달할 때, 소실 될 수 있다.
Resnet과 Highway network는 identity connection을 통해 하나의 layer에서 다음 layer로 signal을 보낸다.
Stochastic depth는 information과 gradient flow를 더 낫게 training하는 동안 무작위로 drop하는 layer로 Resnet을 줄인다.
Fractalnet은 network에서 많은 짧은 path를 유지하는 동안, 큰 depth를 얻기 위해, convolutional block 수가 다른 각각의 병렬 layer sequence을 반복적으로 결합한다.
다른 방법은 network topology와 training 절차로 다름에도 불구하고 앞의 layer에서부터 뒤 layer까지 짧은 path를 만드는 주요 특징을 모두 공유한다.

간단한 connectivity pattern으로 통찰력을 증류하는 architecture를 제안한다.
network에서 layer 간 information flow를 최대로 하기 위해, 우리는 서로 모든 layer를 연결한다.
feed-forward 본성을 보존하기 위해, 각 layer는 모든 이전 layer로부터 추가 input을 얻고 모든 후속 layer에 자체 feature map을 전달한다.
Resnet과 대조해서, layer에 전달하기 전에 summation을 통해 feature를 결합하지 않는다.
그러므로 $l^{th}$ layer는 모든 이전 convolutional block의 feature map을 구성하는 l input을 가진다.
자체 feature map은 모두 $L-l$ 이후의 layer에서 지나간다.
불필요한 feature map을 재학습할 필요가 없기 때문에 dense connectivity pattern의 직관적이지 않은 효과는 기존의 convolutional network보다 더 적은 parameter를 필요로 한다.
기존 feed-forward architecture는 layer에서 layer로 지나는 state를 가지는 알고리즘으로 간주한다.
각 layer는 이전 layer로부터 state를 읽고, 이후 layer에 쓴다.
layer는 state를 바꾸지만 보존되야하는 inforamtion를 전달한다.
Resnet은 추가적인 identity transformation을 통해 분명하게 정보 보존을 한다.
Resnet의 최근 변화는 많은 layer가 매우 작게 기여하고 training하는 동안 무작위로 감소한다는 것이다.
rnn과 비슷한 resnet의 state를 만들지만 resnet의 parameter 수가 더 커진다.
왜냐하면 각 layer가 자체 weight를 가지기 때문이다.
제안된 Densenet architecture는 network에 추가된 information과 보존된 information 간에 분명하게 구별한다.
densenet layer는 network의 collective knowledge에서 feature map의 작은 set을 추가하기에 너무 좁고 바뀌지 않은 feature map을 유지하고 마지막 classifier는 network에서 모든 feature map에 기반된 결정이다.
더 나은 parameter 효율성 외에, densenet의 큰 장점 한가지는 network 내에 train하는데 쉽게 만드는 information과 gradient의 flow가 향상된 것이다.
각 layer는 포함된 deep supervision으로 이어지는 loss function과 기존 input signal에서 gradient로 바로 접근한다.
dense connection은 더 작은 training set size인 task에서 overfitting을 줄이는 regularizing 효과도 있다.
우리는 매우 경쟁력있는 object recognition benchmark task(CIFAR-10, CIFAR-100, SVHN, Imagenet)에서 제안된 architecture를 평가한다.
이 model은 다른 알고리즘보다 훨씬 더 적은 parameter를 필요하는 경향이 있고, benchmark task의 대부분에서 sota를 상당히 능가한다.
DenseNets
network는 non linear transformation $H_{l}()$를 구현하는 각 layer인 L개의 layer로 구성되며, $l$는 레이어를 인덱싱합니다.
$H_{l}()$는 Batch Normalization(BN), rectified linear units(ReLU), Pooling, Convolution(Conv)와 같은 합성 연산이다.
- Resnets
기존의 convolutional feed-forward network는 후속 layer transition을 증가시키는 (l+1)th layer에 input으로써 lth layer의 output을 연결한다.
Resnet은 identity function으로 non linear transformation을 우회하는 skip connection을 추가한다.
Resnet의 장점은 gradient가 후속 layer로부터 이전 layer까지 identity function을 통해 직접적으로 전달하는 것이다.
그러나 identity function과 $H_l$의 output은 network에서 information flow를 방해하는 summation으로 결합된다.
- Dense connectivity

layer 간 information flow를 향상하기 위해 우리는 다른 connectivity pattern을 제안한다.
따라서, lth layer는 input으로서 이전의 모든 layer의 feature map을 받는다.
- Composite function
우리는 세 개 연이은 연산의 합성 함수(BN, ReLU, 3x3 convolution(Conv))인 $H_{l}()$을 정의한다.
- Pooling layers

eq(2)에 사용된 연속 연산은 feature map의 크기가 바뀔 때, 실행 할 수 없다.
그러나, cnn의 본질적인 부분은 feature map의 크기가 변하는 down sampling layer이다.
architecture에서 downsampling을 용이하게 하기 위해, 많은 densely connected dense block으로 network를 나눈다.
block 사이에 layer를 transition layer라고 하고, convolution과 pooling을 한다.
실험에 사용된 transition layer는 batch normalization layer와 1x1 convolutional layer, 2x2 average pooling layer로 구성된다.
- Growth rate
각 함수 $H_l$가 k feature map을 만든다면 lth layer는 $k_0+k \times (l-1)$ input feature map을 가진다.
$k_0$: input layer에 있는 channel 수
densenet과 다른 network 구조 간 중요한 차이는 densenet이 매우 좁은 layer를 가진다는 것이다.
k: network의 증가율
각 layer가 해당 block의 이전의 모든 feature map에 접근할 수 있으므로 network의 ' collective knowledge '에 접근할 수 있다는 것입니다.
증가율은 각 layer가 global state를 기여하는 새로운 information이 얼마인지를 규제한다.
한번 작성된 global state는 network 내 모든 곳에서 접근할 수 있으며, 기존 network architecture와 달리 layer 간에 복제할 필요가 없습니다.
- Bottleneck layers
각 layer는 k개의 output feature map을 만듦에도 불구하고 더 많은 input을 가진다.
1x1 convolution은 input feature map의 수를 줄이기 위해 각 3x3 convolution 전에 bottleneck layer를 진행하므로 연산 효율성을 증가시킨다.
bottleneck layer같은 output이 densenet에서 효과적인 design이라는 것을 알았다.
ex) Densenet-B: $H_l$의 BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)
실험에서, 각 1x1 convolution이 4k feature map을 만든다.
- Compression
소형 model을 향상시키기 위해, transition layer에 있는 feature map의 수를 줄인다.
dense block이 m개의 feature map을 포함한다면, 후속 transition layer가 $\theta m$ output feature map을 만든다.
0<$\theta$<=1은 compression factor를 참조한다.
$\theta$가 1일 때, transition layer를 지나는 feature map의 수가 바뀌지않는다.
- Implementation Details

imagenet을 제외한 모든 dataset에서 densenet은 각각 같은 layer수를 가지는 3개의 dense block을 가진다.
첫번째 dense block에 들어가기 전에, 16 output channel을 가지는 convolution은 input image에 적용한다.
3x3 kernel size를 가지는 convolutional layer에 대해 input을 zero padding한다.
근접한 두 dense block 간에 transition으로 2x2 average pooling에 뒤에 1x1 convolution을 사용한다.
마지막 dense block이 끝날 때, global average pooling이 적용되었고 그 뒤에 softmax classifier를 추가했다.
3개의 dense block에 있는 feature map size는 32x32, 16x16, 8x8이다.
Experiments
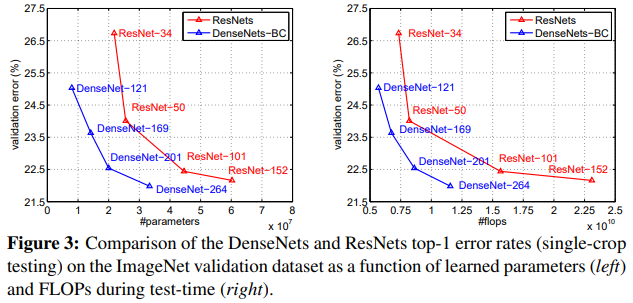



Discusstion


Conclusion
우리는 새로운 CNN architecture인 Desenet을 제안했다.
같은 feature map 크기를 가지는 두 layer 간에 직접적인 connection을 소개한다.
최적화 어려움 없이 densenet은 100개가 넘는 layer로 확장되었다.
Densenet은 overfitting이나 성능 저하 없이 증가하는 parameter로 일정한 향상을 보이는 경향이 있다.
많은 setting으로 매우 경쟁력 있는 dataset에서 sota를 달성했다.
게다가, densenet은 sota를 달성하기 위해 상당히 더 적은 parameter와 적은 연산이 필요하다.
우리가 연구에서 residual network에 대해 최적화된 hyper parameter를 채택하기 때문에 densenet의 향상된 정확도가 더 세부적인 hyper parameter tuning과 learning rate schedule으로 얻어진다고 믿는다.
간단한 connectivity rule에 따라서, Densenet이 identity mapping, deep supervision과 다양한 depth의 특징을 통합한다.
그리고 network 전체에서 feature를 재사용하는 것을 허용하고, 더 소형이고 더 정확한 model을 학습할 수 있다.
소형의 내부 representation과 감소된 feature 중복때문에 densenet은 convolutional feature를 만들 때 다양한 computer vision에서 좋은 feature extractor가 될지도 모른다.
'computer vision > image classification' 카테고리의 다른 글
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2024.01.25 |
|---|---|
| Deep Residual Learning for Image Recognition (2) | 2023.12.04 |
| Very Deep Convolutional Networks For Large-Scale Image Recognition (1) | 2023.10.17 |
| Going deeper with convolutions (0) | 2023.08.22 |
| visualizing and understanding convolutional networks (0) | 2023.06.19 |