Abstract
이 작업에서 우리는 큰 규모의 image recognition 설정에서 정확도에 convolutional network의 효과를 연구한다.
우리의 주요 기여는 매우 작은(3x3) convolutional filter가 있는 architecture를 사용해서 깊이가 증가하는 network를 철저히 평가하는 것인데, 이는 깊이를 16~19개의 weight layer로 푸쉬함으로써 이전 기술 구성에 대한 상당한 개선을 달성할 수 있음을 보여준다.
이 결과는 우리의 팀이 localization과 classification track에서 각각 1등, 2등을 확보하는 우리의 imagenet challenge 2014 제출의 기반이다.
우리는 우리의 표현이 그들의 sota 결과를 달성하는 다른 dataset에 잘 일반화가 된 것을 보여준다.
우리는 computer vision에서 심층적인 시각적 표현의 사용에 대한 추가 연구를 가능하게 하기 위해 우리의 두가지 가장 성능이 좋은 convnet model을 공개적으로 제공했다.
Introduction
convolution network는 최근 imagenet과 같은 대규모 공개 이미지 저장소와 GPU 또는 대규모 분산 클러스터와 같은 고성능 컴퓨팅 시스템으로 인해 가능해진 large scale image와 video recognition에서 큰 성공을 거두었다.
특히, 깊은 visual recognition architecture의 발전에서 중요한 역할은 deep convnet에 있는 고차원의 얕은 feature encoding으로부터 큰 규모의 image classification system의 적은 발전에 대한 시험의 역할을 하는 imagenet large scale visual recognition challenge에 의해 수행되었다.
convnet이 computer vision분야에서 점점 더 필수가 되면서 더 나은 정확도를 달성하기 위해 Krizhevsky 등의 원래 architecture를 개선하려는 많은 시도가 있었다.
예를 들어, ILSVRC 2013에서 가장 성능이 좋은 제출은 더 작은 receptive window size와 첫번쨰 convolutional layer의 더 작은 stride를 활용했다.
다른 개선사항은 전체 image와 많은 규모에 걸처 network를 빽뺵하게 training하고 testing하는 것을 처리한다.
이 논문에서, 우리는 convnet architecture 디자인의 다른 중요한 측면인 깊이를 다룬다.
network 끝에서, 우리는 architecture의 다른 parameter를 고치고 모든 layer에서 매우 작은(3x3) convolution filter의 사용때문에 실현가능한 더 많은 convolutional layer를 더함으로써 network의 깊이를 꾸준히 증가한다.
결과적으로, 우리는 ILSVRC classification과 localization task에서 sota 정확도를 달성할 뿐만 아니라 그들이 상대적으로 간단한 pipeline의 부분을 사용할 때 훌륭한 성능을 달성하는 다른 image recognition dataset에도 적용가능한 상당히 더 많이 정확한 convnet architecture를 제시한다.
우리는 추가 연구를 가능하게 하기 위해 우리의 최고의 성능을 보이는 model 두 가지를 발표했다.
Convnet configurations
* Architecture
training하는 동안, 우리의 convnet input은 고정된 크기인 224x224 RGB image이다.
우리가 하는 유일한 전처리는 평균 RGB값을 뺴고 각 pixel로부터 training set에 계산되어진다.
이 image는 우리가 매우 작은 receptive field(3x3)로 filter를 사용하는 convolutional layer의 stack을 통과한다.
구현 중 한가지에서 우리는 input 채널의 선형 변환으로 간주될 수 있는 1x1 convolution filter를 활용한다.
convolution stride는 1 pixel로 고정되어졌다.
conv layer input의 공간적인 padding은 spatial 해상도가 convolution 후에도 보존되어졌다.
즉, padding은 3x3 conv layer에 대한 1픽셀이다.
공간적인 pooling은 conv layer 중 일부를 뒤따르는 5개의 max pooling layer에 의해 수행되어졌다.
max pooling은 stride 2로 2x2 pixel window가 수행되어졌다.
convolutional layer의 stack 뒤에는 3개의 fc layer가 왔다.
1,2번째는 4096개의 채널을 가지고 3번째는 1000-way ILSVRC classification을 수행한다.
그러므로 1000개의 채널을 포함한다.
마지막 layer는 softmax layer이다.
fc layer의 구성은 모든 network에서 같다.
모든 hidden layer는 ReLU를 사용한다.
우리는 sec4에 보여진 것처럼 우리의 network에 LRN 정규화를 포함하는 것에 주목한다.
정규화는 ILSVRC dataset에서 성능을 향상시키지는 않지만 증가된 memory 소비와 연산 시간으로 이어진다.
* Configurations
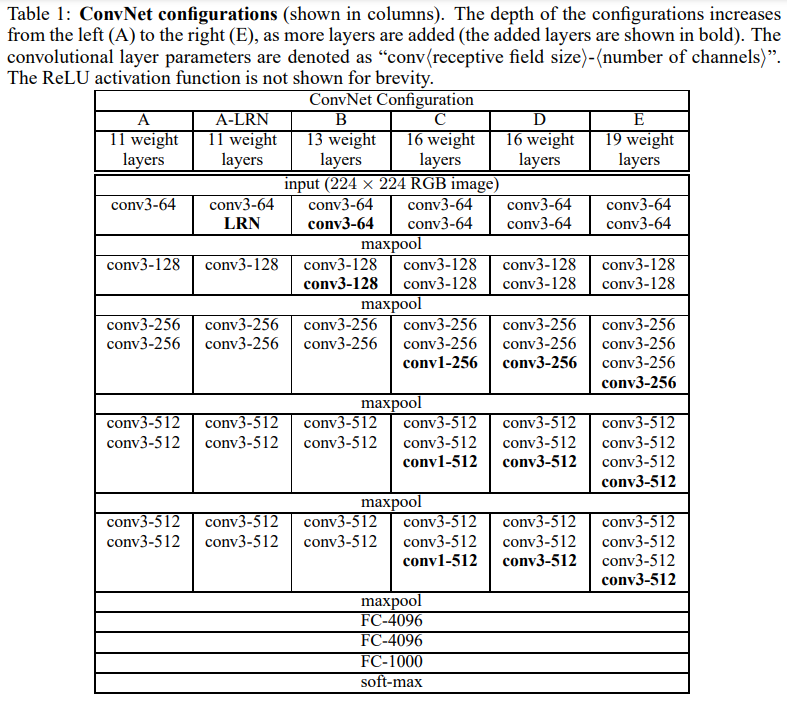
network A에 있는 11개의 weight layer로부터 network E에 있는 19개의 weight layer까지 깊이가 다르다.
conv layer의 unit 수는 첫번째 layer에서 64개로 시작해서 각 max poolng layer 이후 2배씩 증가해서 512개에 도달할 때까지 다소 작다.

표2에서 우리는 각각 구현하는 동안 parameter의 수를 보고한다.
큰 깊이에도 불구하고, 우리의 network에서 weight의 수는 더 큰 conv layer unit 수와 receptive field를 가진 더 많이 얕은 network에서 weight 수보다 더 좋지 못하다.
* Discussion
우리의 convnet 구현은 ILSVRC 2012와 ILSVRC 2013 대회의 가장 좋은 성능을 보이는 출품작에서 사용된 하나와 꽤 다르다.
첫번째 conv layer에서 상대적으로 큰 receptive field나 stride 2로 7x7을 사용하기보다는, 우리는 모든 pixel에서 input과 복잡하게 얽혀있는 전체 network 내내 매우 작은 3x3 receptive field를 사용한다.
두 개의 3x3 conv layer의 stack은 5x5인 효과적인 receptive field를 가지는 것으로 보는 것이 쉽다.
이러한 세 개의 layer는 7x7인 효과적인 receptive field를 갖는다.
- 7x7 layer 하나 대신 3개의 3x3 conv layer의 stack을 사용해서 얻는 것은?
- 더 많이 차별적인 decision function을 하게 만드는 단일 하나 대신에 3개의 non linear rectification layer를 통합한다.
- parameter 수를 줄임
3개의 layer의 3x3 convolution stack의 입력과 출력 모두 C개의 채널을 갖는다고 가정하면, stack은 27C^2 weight로 파라미터화되어진다.
동시에 하나의 7x7 conv layer는 49C^2 parameter가 필요하다.
이것은 7x7 conv filter에 정규화를 적용해서 3x3 filter를 통해 분해되도록 하는 것을 볼 수 있다.
1x1 conv layer의 통합은 conv layer의 receptive field에 영향받는 것 없이 decision function의 비선형을 증가시키는 방법이다.
우리의 경우에 1x1 convolution은 같은 차원의 공간에 근본적으로 선형 투영이 있음에도 불구하고 추가적인 비선형은 rectification 함수에 의해 진행된다.
그것은 1x1 conv layer가 Lin et al의 "network in network"에 활용되어졌다는 것에 주목해야한다.
작은 크기의 convolution filter는 ciresan et al에 의해 이전에 사용되어졌지만 그들의 network는 우리의 것보다 덜 깊은 것이 중요하고 그들은 큰 규모의 ILSVRC dataset을 평가하지 않았다.
goodfellow et al은 street number recognition의 task로 깊은 convnet을 적용했고 증가된 깊이가 더 좋은 성능으로 이끄는 것을 보였다.
ILSVRC 2014 classification task의 최고의 성능을 보이는 출품작인 googlenet은 우리의 작업과 관계없이 발전되어졌지만 매우 깊은 convnet과 작은 convolution filter에 기반된 것과 비슷하다.
그러나, 그들은 network 토폴리지는 우리의 것보다 더 복잡하고 feature map의 공간적인 해상도는 연산의 양을 줄이기 위해 첫번째 layer에서 더 많이 줄였다.
sec 4.5에서 보여지는 것처럼, 우리의 model은 단일 network classification 정확도면에서 Szegedy et al의 것보다 성능이 뛰어나다.
Classification framework
* Training
학습은 momentum과 같이 mini batch gradient descent를 사용하는 다항의 logistic regression 함수를 최적화함으로써 수행되어졌다.
- network initialization
- batch size: 256
- momentum: 0.9
학습은 처음 두개의 fc layer에 weight decay와 dropout 정규화로 정규화되어졌다.
learning rate는 10^-2로 최초로 설정되었고 그 후 validation set 정확도가 향상되는 것이 멈췄을 때 10배 감소되어졌다.
전체적으로, learning rate는 3배 감소되어졌고 학습은 370k iteration(74 epoch) 후에 멈췄다.
우리는 많은 양의 parameter와 network의 깊은 깊이가 비교되어짐에도 불구하고, 더 깊은 깊이와 더 작은 cov filter 크기에 의해 부과된 암시적 정규화때문에 network가 수렴하는데 더 적은 epoch가 필요하다고 추측합니다.
network weight 초기설정은 중요하다
안 좋은 초기설정은 깊은 network에서 gradient의 불안정때문에 학습을 피할 수 있기 때문이다.
이 문제를 피하기 위해서, 우리는 무작위 초기 설정으로 학습되기 위해 충분히 얕은 구현 A로 학습을 시작했다.
그 후, 더 깊은 구조를 학습할 때, 우리는 net A의 layer로 처음 4개의 convolutional layer와 마지막 3개의 fc layer를 초기설정했다.
우리는 학습하는 동안 변화하는 것을 허용하는 사전 초기설정된 layer에 대해 learning rate를 감소하지 않는다.
무작위 초기설정을 위해, 우리는 0인 평균과 10^-2 분산을 가진 정규 분포로부터 weight를 샘플링했다.
bias는 0으로 초기설정되었다.
논문 제출 후에 우리는 Glorot과 Bengion의 무작위 초기설정 절차를 사용함으로써 pretraining없이 weight를 초기설정하는 것이 가능하다는 것을 알았다는 것은 주목할 가치가 있다.
고정된 크기인 224x224 convnet input image를 얻기 위해, 그들은 rescale된 training image로부터 무작위로 crop되어졌다.
- argument
- random horizontal flipping
- random RGB colour shift
- Training image size
S: Convnet input이 crop된 isotropically rescale된 training image의 가장 작은 변
crop size가 224x224로 고정되어있지만, 원칙에서 S는 224이상의 값을 가질 수 있다.
S가 224인 경우 crop은 training image의 가장 작은 변에 걸처 전체 image 통계를 캡처한다.
S가 224보다 큰 경우 crop은 object 부분이나 작은 object를 포함하는 image의 작은 부분에 해당될 것이다.
- training scale S를 설정하는 것에 대한 두가지 접근법
1. single scale training에 해당하는 S를 수정하는 것
: 우리의 실험에서, 우리는 두가지 고정된 규모(S=256,384)에서 훈련된 model을 평가했다.
convnet 구현을 고려해볼 때, 우리는 S를 256으로 사용하는 network로 처음 학습했다.
S가 384인 network의 학습 속도를 높이기 위해 256인 S를 가지고 pretrain된 weight를 가지고 초기설정되어졌고, 우리는 더 작은 초기의 learning rate인 10^-3을 사용했다.
2. 각 training image가 특정 범위인 [S_min,S_max]로부터 무작위로 sampling하는 S에 의해 개별적으로 rescale되는 multi scale training
: image에 있는 object는 크기가 다를 수 있기 때문에 학습하는 동안 고려하는 것이 좋다.
이것은 single model이 넓은 범위의 scale로 object를 인지하기 위해 학습되어지는 scale jittering에 의해 training set을 augmentation하는 것으로 간주 할 수 있다.
속도 상의 이유로, 우리는 고정된 384인 S로 pretrain된 같은 구현을 가지고 single scale model의 모든 layer를 fine tuning함으로써 multi scale model을 학습했다.
* Testing
test할 때, 학습된 convnet과 input image를 고려해볼 때, 그 다음 방법에서 분류되어졌다.
1. Q로 표시한 미리정의된 가장 작은 image 변에서 등방성으로 rescale되어졌다.
-> Q가 training scale인 S와 필수적으로 동등하지 않아도 된다
2. network는 비슷한 방법에서 rescale된 test image에 dense하게 적용되어졌다.
-> 즉, fc layer는 convoluton layer로 먼저 변환되었다.
결과로 초래된 fully convolutional network는 전체 image에 적용되어졌다.
결과는 channel 수가 class 수와 동일하고 input image 크기에 따라 가변 공간 해상도를 갖는 class score map이다.
3. image에 대한 class score의 고정된 크기의 vector를 얻기 위해, class score map이 공간적으로 평균되어졌다.
test set augmentation: horizontal flipping
원본과 뒤집힌 image의 softmax layer 후에 image에 대한 최종 점수 낸 것을 평균 냈다.
fully convolutional network는 전체 image에 적용되어지므로, test할 때, 각 crop에 대해 network 재계산이 필요하므로 덜 효율적인 많은 crop을 sample할 필요가 없다.
동시에, 많은 양의 crop을 사용하면 fully convolutional network와 비교해서 input image의 더 좋은 sampling의 결과가 되므로 향상된 정확도를 보인다.
또한 multi crop 평가는 다른 convolution boundary 조건때문에 dense evalutaion을 상호보완한다.
crop을 convnet에 적용할 때, convolve된 feature map은 0으로 padding되는 반면에
dense evaluation의 경우 같은 crop에 대한 padding이 종합적인 network receptive field를 상당히 증가시키는 image의 이웃한 부분에서 온다.
그래서 더 많은 context가 capture되어졌다.
우리는 실제 많은 crop의 증가된 연산 시간이 정확도에서 잠재적인 이득을 정당화하지 않다고 믿지만 참고로 우리는 szegedy et al에 의해 사용된 4개의 scale로 144개의 crop과 비슷한 3개의 scale로 총 150개의 crop에 대해 scale당 50개의 crop을 사용하는 우리의 network를 평가한다.
* Implementation Details
우리의 구현은 공개적으로 사용가능한 C++ caffe toolbox로부터 되지만 다중 scale에 full size image로 학습하고 평가할뿐만 아니라 단일 시스템에 설치된 다중 GPU에 학습과 평가를 실행하는 것을 허용하는 많이 중요한 수정을 포함한다.
다중 GPU 학습은 data paralleism을 이용하고, 각 GPU에서 병렬적으로 처리되는 여러개의 GPU batch로 학습하는 image의 각 batch를 분리함으로써 수행한다.
GPU batch gradient가 계산되어지고 나서, 그들은 최대 batch의 gradient를 얻기 위해 평균내졌다.
gradient 연산은 GPU들에 동시에 발생한다.
그래서 결과는 단일 GPU로 학습했을 때와 정확히 같다.
network의 다른 layer에 의해 model과 data parallelism을 사용하는 convnet의 학습 속도를 올리는 더 정교한 방법이 제안되어졌다.
우리는 개념적으로 우리의 더 간단한 계획이 단일 GPU를 사용했을 때보다 기성품 4개의 GPU시스템에서 3.75배 속도향상을 제공하는 것을 알았다.
4개의 NVIDIA Titan Black GPU를 가진 시스템에서, 단일 network를 학습하는 것은 이 구조에서 2~3주 걸린다.
Classification Experiments
- Dataset
- data split: training(1.3M image), validation(50k image), testing(class label이 있는 100k image)
classification 성과는 top1과 top5 error를 사용해서 평가됐다.
top1 error를 사용한 것은 multi class classification error(틀리게 분류된 image 비율)이고 top5 error를 사용한 것은 ILSVRC에 사용된 주요 평가 기준이고 ground truth 카테고리가 예측된 카테고리 top5를 벗어나는 image의 비율로 계산되어졌다.
대다수의 실험에서 우리는 validation set을 test set으로 사용했다.
어떤 실험은 test set을 수행하고 ILSVRC 2014 대회에 "VGG" team 출품작으로 공식적인 ILSVRC 서버에 제출했다.
* single scale evaluation

test image 크기는 고정된 S에 대해 Q와 S가 같고 불안정된 S ∈ [S_min, S_max]에 대해 Q = 0.5(S_min+S_max)로 설정했다.
먼저, 우리는 사용하는 local response normalization은 normalization layer없이 model A에서 향상하지 않는다.
따라서 우리는 더 깊은 구조에서 normalization을 쓰지 않는다.
두번째, 우리는 classification error가 증가된 convnet 깊이(A에 있는 11개의 layer로부터 E에 있는 19개의 layer까지)로 감소하는 것을 관찰한다.
특히, 같은 깊이에도 불구하고, 구현 C는 network 내내 3x3 conv layer를 사용하는 구현 D보다 더 나쁜 성과였다.
이것은 추가적인 비선형성이 도움이 되지만 trivial receptive field로 conv filter를 사용함으로써 공간적인 context를 caputre하는 것은 중요하다.
깊이가 19개의 layer일 때 우리의 구조의 error율은 포화시키지만 더 깊은 model은 더 큰 dataset에 대해 이로울지도 모른다.
우리는 하나의 5x5 conv layer를 가진 3x3 conv layer의 각 쌍을 대체함으로써 B로부터 파생된 5개의 5x5 conv layer을 가진 얕은 network로 network B와 비교된다.
얕은 network의 top1 error는 작은 filter들을 가지는 깊은 network가 더 큰 filter들을 가진 얕은 network을 능가하는 것을
확인하는 B의 top1 error보다 7% 더 높았다.
마지막으로, training time에서 scale jittering은 단일 scale이 test시간에 사용됨에도 불구하고 고정된 가장 작은 변을 가진
image로 학습하는 것보다 더 나은 결과를 보였다.
이것은 scale jittering을 통해 training set augmentation은 multi scale image 통계를 capture하는 것에 대해 도움이 된다는 것을 확인한다.
* Multi-Scale Evaluation
single scale에서 평가된 convnet model을 사용할 때, 우리는 test 시 scale jittering의 효과를 지금 평가한다.
class 사후확률의 결과를 평균낸 다음 test image의 여러 개의 rescale된 version에서 model을 실행하는 것으로 구성한다.
training과 testing scale 간에 큰 불일치는 성능을 떨어트리는 점에 고려하여, 고정된 S로 학습된 model은 학습 크기인 Q = {S−32, S, S+32}에 가까운 3개의 test image 크기에 대해 평가되어졌다.
동시에, 학습 시 scale jittering은 test 시 넓은 범위의 scale에 적용되는 network를 허용한다.
그래서 변수 S ∈ [Smin; Smax]로 학습된 model은 더 큰 범위의 크기인 Q = {Smin, 0.5(Smin + Smax), Smax}에 평가되어졌다.

표4에서 제시된 결과는 test 시에 scale jittering는 더 나은 성능을 이끄는 것을 나타낸다.
이전처럼, 가장 깊은 구현은 가장 좋은 성능을 보이고, scale jittering은 고정된 가장 작은 변인 S로 학습한 것보다 더 나았다.
validation set에서 가장 좋은 single network 성능은 24.8%(top1 error), 7.5%(top5 error)이다.
test set에서, 구현E는 7.3% top5 error를 달성한다.
* Multi-crop evaluation

표 5에서 우리는 multi crop evaluation을 가진 dense한 convnet 평가를 비교한다.
우리는 softmax output을 평가함으로써 두가지 평가 기술의 상보성을 평가한다.
볼 수 있듯이, multiple crop을 사용한 성능은 dense evaluation보다 약간 더 낫고, 조합이 각각 성능을 능가시키므로
두가지 방법은 정말 상호보완적이다.
위에 언급한 바와 같이, 우리는 이것이 convolution boundary 조건의 다른 대우때문이라는 것을 가설한다.
* Convnet fusion
지금까지, 우리는 개인적인 convnet model의 성능을 평가했다.
실험의 이 부분에서, 우리는 softmax class 사후확률을 평균냄으로써 몇몇 model의 output을 결합한다.
이것은 model의 상보성때문에 성능이 오르고, 2012년도와 2013년에 가장 좋은 ILSVRC 제출에 사용되었다.
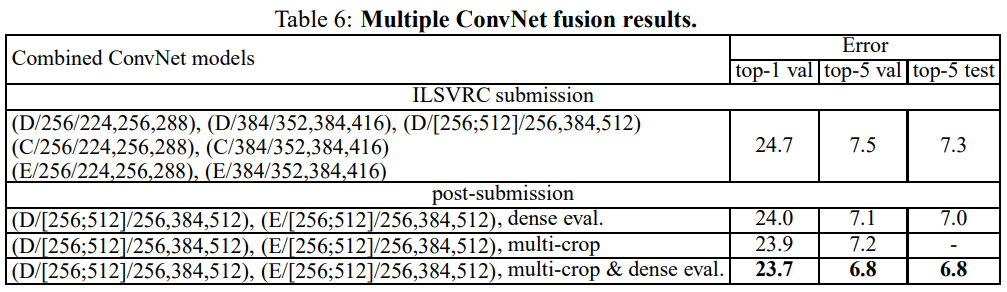
결과는 표6에 보여졌다. ILSVRC 제출 시간 지나서 우리는 multi scale model D뿐만 아니라 single scale network도 학습했다.
7개의 network의 ensemble 결과는 7.3% ILSVRC test error를 가진다.
제출 후에, 우리는 dense evaluation을 사용해서 7.0%, 결합된 dense와 multi crop evaluation를 사용해서 6.8%로 test error를 줄이는 가장 성능이 좋은 두개의 multi scale model의 ensemble을 고려했다.
참고로, 우리의 최고 성능을 내는 single model은 7.1%를 달성한다.
* Comparison with the state of the art

마침내, 우리는 표7에서 sota를 가진 우리의 결과와 비교한다.
ILSVRC 2014 challenge의 classification task에서, 우리의 "VGG" team은 7개의 model의 ensemble을 사용하는 7.3% test error로 2위를 확보했다.
제출 후에, 우리는 2개의 model의 ensemble을 사용해서 6.8%로 error rate를 줄였다.
표7에서 알 수 있듯이, 우리의 매우 깊은 convnet은 ILSVRC 2012와 ILSVRC 2013 대회에서 가장 좋은 결과를 달성했던 이전의 세대의 model을 상당히 능가시켰다.
우리의 결과는 classification tastk 우승자에 대하여 경쟁력이 있고 외부 training data로 11.2%, 외부 training data 없이 11.7%를 달성하는
ILSVRC 2013 우승자 제출 clarifai를 상당히 능가한다.
우리의 가장 좋은 결과는 대부분의 ILSVRC 제출에 사용된 것보다 상당히 적은 두 개 model만 결합함으로써 달성됐다는 점을 고려하면 놀랄 만한 일이다.
singel net 성능에 대해서, 우리의 구조는 0.9%로 single googlenet을 능가하는 가장 좋은 결과를 달성한다.
특히, 우리는 Lecun et al의 고전적인 convnet 구조로부터 벗어나지 않지만 깊이를 상당히 증가시킴으로써 성능을 향상했다.
Conclusion
이 작업에서, 우리는 큰 규모의 image classification을 위해 매우 깊은 convolutional network를 평가했다.
representation 깊이는 classification 정확도에 도움이 되며 imagenet challenge dataset의 sota 성능은 깊이가 크게 증가된 기존 convnet architecture을 사용해서 달성할 수 있음이 입증되었다.
appendix에서, 우리 model은 광범위한 task와 dataset에 잘 일반화되어 덜 깊은 image representation을 중심으로 구축된 더 복잡한 recognition pipeline과 일치하거나 그보다 뛰어난 성능을 발휘한다는 것을 보여준다.
A. Localisation
논문의 본체에서 우리는 ILSVRC challenge에서 classification task를 고려했고, 다른 깊이의 convnet 구조의 평가를 통해서 수행했다.
이 section에서, 우리는 우리가 25.3% error로 2014년에 우승한 challenge의 localisation task을 진행한다.
이것은 single object bounding box가 class의 object 실제 수에 관계없이 각각의 top 5 class에 대해 예측되는 object detection의 특별한 경우로 보일 수 있다.
이것을 위해 우리가 적은 수정으로 ILSVRC 2013 localisation challenge의 우승자인 sermanet et al의 방법을 채택한다.
A.1 Localisation convnet
object localisation을 하기 위해, 우리는 마지막 fc layer가 class 점수 대신에 bounding box location을 예측하는 매우 깊은 convnet을 사용한다.
bounding box는 가운데 좌표, 너비, 높이로 4D vector 저장함으로써 나타내졌다.
bounding box 예측은 모든 class나 클래스별로 공유되어졌다.
이전 경우에서, 최종 layer는 4D인 반면에 후자는 4000D이다.
마지막 bounding box prediction layer을 제외하고 우리는 16개의 weight layer를 포함하는 convnet 구조 D를 사용하고,
classification task에서 가장 성능이 좋다고 발견됐다.
- Training
localisation convnet의 학습은 convnet 분류 학습과 비슷하다.
주요 차이는 우리가 ground truth로부터 예측된 bounding box의 편차에 패널티를 부과하는 euclidean loss로 logistic regression 함수를 대체하는 것이다.
우리는 256인 S와 384인 S인 single scale에 각각 두개의 loacalisation model에 학습했다.
학습은 해당하는 classification model로 초기설정되어졌고 초기 learning rate는 10^-3으로 설정했다.
우리는 모든 layer를 fine tuning하는 것과 처음 두개의 fc layer만 fine tuning하는 것 둘 다 분석한다.
마지막 fc layer는 무작위로 초기 설정과 맨 처음부터 학습되었다.
- Testing
우리는 두개의 testing protocol을 고려한다.
첫번째 것은 validation set에서 다른 network 수정과 비교하는 것으로 사용됐고, ground truth class에 대해 bounding box 예측만 고려한다.
bounding box는 image의 중심 crop에만 network를 적용함으로써 얻어졌다.
두번째는, 완전한 testing 절차는 전체 image에 대한 localisation convnet의 dense한 적용을 기반으로한다.
차이는 class score map을 대신해서 마지막 fc layer의 output은 bounding box prediction의 set이라는 것이다.
최종 예측을 위해 우리는 먼저 공간적으로 가까운 예측을 병합하는 Sermanet et al의 그리디 병합 절차를 활용하고,
ConvNet 분류에서 얻은 클래스 점수를 기준으로 평가합니다.
여러개의 localisation convnet이 사용됐을 때, 우리는 bounding box 예측의 합집합을 먼저 가지고 그 이후 합집합에서 병합 절차를 실행한다.
우리는 bounding box 예측의 공간적인 해상도를 증가하고 결과를 더 향상시킬 수 있는
sermanet et al의 multiple pooling offset 기술을 사용하지 않았다.
A.2 Localisation experiments
이 section에서 우리는 가장 성능이 좋은 localisation 설정을 먼저 결정하고, 그 이후 완전한 시나리오에서 평가한다.
localisation error는 ILSVRC 기준에 따라 측정되어졌다.
즉, 만약에 ground truth box에 대한 IOU 비율이 0.5보다 높다면 bounding box 예측은 맞다고 간주되어졌다.
- Settings comparison

표8에서 알 수 있듯이, per class regression(PCR)은 PCR이 SCR에 의해 능가되어지는 sermanet et al의 결과와 다르게
class agnostic single class regression(SCR)를 능가한다.
우리는 localisation task에 대해 모든 layer를 fine tuning하는 것이 fc layer만 fine tuning하는 것보다 분명하게 더 나은 결과를 이끄는 것에 주목한다.
이 실험에서, 가장 작은 image 변은 S를 384로 설정했다.
S가 256인 결과는 같은 행동을 나타내므로 간결성을 위해 표시되지 않았다.
- Fully-fledged evaluation
최고의 localisation setting을 결정할 때, 우리는 fully fledged 시나리오에서 localisation setting을 지금 적용한다.
top 5 class label은 우리의 최고 성능을 보이는 classification system을 사용해서 예측되어졌고 multiple dense하게 계산된
bounding box 예측은 sermanet et al의 방법을 사용해서 병합되어졌다.

표 9에서 볼 수 있듯이 ground truth 대신에 top5로 예측된 class를 사용함에도 불구하고
전체 image에 convnet localisation의 적용은 center crop을 사용해서 비교된 결과를 상당히 향상한다.
classification task와 비슷하게도, 여러개의 scale을 테스트하는 것과 multiple network의 예측을 결합하는 것은 성능을 더욱 향상한다.
- Comparison with the state of the art

우리는 표10에서 sota로 최고의 localisation 결과를 비교한다.
25.3% test error로 우리의 vgg팀은 ILSVRC 2014의 localisation challenge에서 이겼다.
특히, 우리가 적은 scale을 사용했고 해상도 향상 기술을 이용하지 않음에도 불구하고
우리의 결과는 ILSVRC 2013 우승자 overfeat의 결과보다 상당히 더 낫다.
우리는 이 기술이 우리의 방법에 포함된다면 더 나은 localisation 성능이 달성될 수 있다는 것을 예상한다.
이것은 성능 발전이 너무 깊은 convnet에 의해 되는 것을 나타난다.
우리는 더 강력한 representation 외에 더 간단한 localisation 방법으로 최고의 결과를 가진다.
B. Generalisation of very deep features
이전 section에서 우리는 ILSVRC dataset에서 매우 깊은 convnet의 학습과 평가를 상의한다.
이 section에서, 우리는 overfitting때문에 대규모 model을 처음부터 학습하는 것이 불가능한 다른 소규모 dataset의 feature extractor로 ILSVRC에서 pretrain된 convnet을 평가한다.
최근에, ILSVRC에 학습된 깊은 image representation은 그들이 큰 차이로 hand crafted representation을 능가하는 다른 dataset에 잘 일반화한다는 것을 나타내는 것처럼 그러한 사용 case에서 많은 흥미를 가진다.
작업 라인을 따라서, 우리는 우리의 model이 sota 방법에서 활용된 많이 얕은 model보다 더 나은 성능을 이끈다면 연구한다.
평가에서 우리는 ILSVRC에서 최고의 classification 성능을 가진 두개의 model(Net-D와 Net-E 구현)을 고려한다.
ILSVRC에서 pretrain된 convnet을 활용하기 위해, 다른 dataset에서 image classification에 대해, 우리는 마지막 fc layer를 제거하고 multiple location과 scale로 집계된 image featgure로서 끝에서 두번쨰 layer의 4096차원 활성화 함수를 사용한다.
image descriptor 결과는 target dataset에서 학습된 선형 SVM 분류기로 L2 normalise되었고 결합했고 target dataset에서 학습했다.
단순화를 위해, pretrain된 convnet weight는 고정된 상태로 유지했다.
feature 종합은 ILSVRC 평가 절차에서 간단한 방식으로 수행되어졌다.
즉, image는 가장 작은 변이 Q와 동일하기 위해 우선 rescale되어졌고 그 이후, network는 image plane에 dense하게 적용되어졌다.
우리는 4096차원 image descriptor을 만드는 feature map 결과에 global average pooling을 수행한다.
descriptor는 수평으로 뒤집힌 image의 descriptor를 써서 평균냈다.
section 4.2에서 보여지는 것처럼, multiple scale에 걸쳐 평가는 유익하다.
그래서 우리는 여러가지 scale인 Q에 걸처 feature를 추출한다.
stack하는 것은 scale의 범위에서 image statistic을 최적으로 결합하는 방법을 학습하는 그 다음의 classifier를 허용한다.
그러나 이것은 증가된 descriptor 차원수의 비용에 접근한다.
우리는 실험에서 design 선택의 상의로 돌아간다.
우리는 그들의 각각 image descriptor를 stack함으로써 실행되는 두개의 network를 사용해서 계산된 feature의 후기융합을 평가한다.
- Image classification on VOC 2007 and VOC 2012
우리는 pascal voc 2007과 voc 2012 benchmark의 image classification task에서 평가를 시작한다.
이 dataset은 10k와 22.5k image 각각 포함하고 각 image는 20개의 object 카테고리에 해당하는 하나나 여러개의 label로 annotate한다.
voc 조직자는 training, validation, test data로 미리 정의된 분할을 제공한다.
recognition 성능은 class에 mAP를 사용해서 측정한다.
특히, voc 2007과 voc 2012의 validation set에서 성능을 검토함으로써, 우리는 image descriptor를 합치는 것이 stacking으로 동시에 합쳐서 성능을 평균내서 multiple scale을 계산했다.
우리는 voc dataset에서 object가 다양한 scale로 나타나는 것이 fact이기 때문이라고 가설한다.
그래서 classifier가 착취할 수 있는 특정한 scale별 semantic이다.
평균 내는 것은 descriptor 차원수를 늘리지 않는 장점을 가지므로, 우리는 scale의 넓은 범위(Q ∈ {256, 384, 512, 640, 768}) image descriptor를 합칠 수 있다.
{256, 384, 512}의 더 작은 범위로 향상은 상당히 미미한 것(0.3%)을 통해 가치가 없다.

test set 성능은 표11에서 다른 방법으로 보고되어지고 비교되어진다.
우리의 network인 Net-D와 Net-E는 voc dataset에 이상적인 성능을 나타내고 그들의 결합은 결과에 약간 향상을 준다.
우리의 방법은 6%보다 더 많은 chatfield et al의 이전의 최고의 결과를 능가하는 ILSVRC dataset에 pretrain된 image representation에서 새로운 sota를 설정한다.
voc 2012에서 mAP가 1% 더 나은 wei et al의 방법은 확장된 voc dataset에서 semantic하게 가까운 추가적인 1000개의 카테고리를 포함하는 2000개의 class인 ILSVRC dataset에 pretrain됐다.
object detection이 assist된 clasification pipeline을 가진 fusion으로부터 장점을 가진다.
- Image classification on Caltech 101 and Caltech 256
이 section에서 우리는 caltech 101과 caltech 256 image calssification benchmark에서 매우 깊은 feature을 평가한다.
caltecth 256이 31k image와 257개의 class로 더 큰 반면에 caltecth 101은 102개의 class들로 label된 9k image를 포함한다.
이 dataset에서 기존 평가 protocal은 traing과 test data로 여러개로 random하게 분할을 하는 것이고, 평균 class recall로 측정되는 분할의 평균 recognition 성능을 보고한다.
caltech 101에서 chatifield et al, zeiler & fergus, he et al에 따라서, 우리는 각 split이 class당 30개의 training image를 포함하기 위해서 training과 test data로 3개의 random split을 했고
class당 50개의 test image까지이다.
caltecth 256에서 우리는 class당 60개의 training image를 포함하는 3개의 split을 만들었다.
각 split에서 training image의 20%는 hyper parameter 선택을 위해 validation set에서 사용되어졌다.
우리는 voc와 달리 caltech dataset에서 multiple scale에 계산된 descriptor의 stacking은 averaging이나 max pooling보다 더 나은 성능을 보인다.
caltech image에서 object는 전체 image를 일반적으로 차지하는 것이 fact로 설명되어질 수 있다.
그래서 multi scale image feature은 semantical하게 다르고 stacking은 앞에 언급한 scale별 representation를 착취하기 위해 classifier를 허용한다.
우리는 3개의 scale(Q ∈ {256, 384, 512})을 사용한다.
우리의 model은 표11에서 sota와 서로 비교되어졌다.
알 수 있는 바와 같이, 더 깊은 19개의 layer인 Net-E 성능은 16개의 layer Net-D보다 더 나았고 그들의 결합은 성능을 더 향상시킨다.
caltech 101에서, 우리의 representation은 he et al의 방법과 경쟁력이 있다.
그러나 voc 2007에서 성능이 우리의 network보다 상당히 더 나쁘다.
caltecth 256에서 우리의 feature는 큰 차이(8.6%)로 sota를 능가한다.
- Action Classification on VOC 2012
우리는 사람이 수행하는 action의 bounding box가 주어진 single image로부터 action class를 예측하는 것으로 구성하는
pascal voc 2012 action classification task에서 최고의 성능은 보이는 image representation을 평가했다.
dataset은 11개의 class로 label된 4.6k training image를 포함한다.
voc 2012 object classification task와 비슷하게도 성능은 mAP를 사용해서 측정되어졌다.

- 두개의 training setting
- 전체 image에 convnet feature을 계산하는 것과 제공된 bounding box를 무시하는 것
- 전체 image와 제공된 bounding box에서 feature를 계산하는 것과 마지막 representation을 얻기 위해 stacking한다.
결과는 표12에서 다른 방법과 비교되어짐.
- Other recognition tasks
우리의 model의 공개 발표때문에, 그들은 더 얕은 representation을 지속적으로 능가하는 넓은 범위의 image recognition task에 대한 research community에 의해 적극적으로 사용되어진다.
예를 들어, girshick et al은 우리의 16개 layer model로 krizhevsky et al의 convnet을 대체함으로써 object detection 결과의 상태를 달성한다.
krizhesky et al의 많이 얕은 구조에 비슷한 이득은 semantic segmentation, image caption generation, texture과 material recognition에서 관찰되어진다.
'computer vision > image classification' 카테고리의 다른 글
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2024.01.25 |
|---|---|
| Deep Residual Learning for Image Recognition (2) | 2023.12.04 |
| Going deeper with convolutions (0) | 2023.08.22 |
| visualizing and understanding convolutional networks (0) | 2023.06.19 |
| ImageNet Classification with Deep Convolutional Neural Networks (1) | 2023.05.09 |