Abstract
정확하고 효율적인 object detection을 위해 region에 기반된 fully convolutional network를 제안
비용이 많이 드는 region당 subnetwork를 수백번 적용하는 이전 region에 기반된 detector(Fast/Faster R-CNN)과 대조해서, R-FCN은 전체 image에 공유된 거의 모든 연산으로 fully convolution한다.
이것을 하기위해, 우리는 image classification에서 translation invariance와 object detection에서 translation variance 간에 딜레마를 다루기 위해 position sensitive socre map을 제안한다.
R-FCN은 object detection에 대한 Resnet과 같은 fully convolutional image classifier backbone을 사용한다.
101 layer Resnet으로 PASCAL VOC dataset에서 경쟁력 있는 결과를 보였다.(83.6 mAP: 2007 set)
그 동안, 결과는 test에서 Faster R-CNN보다 2.5~20배 더 빠른 image당 170ms 속도를 달성한다.
Introduction
- ROI pooling layer로 두 subnetwork로 나눠진 object detection에 대한 deep network
1. roi의 독립적인 공유된 fully convolutional subnetwork
2. 연산을 공유하지 않는 ROI별 subnetwork
두 subnetwork는 선구적인 classification architecture(alexnet, vgg net)으로부터 발생했고, image classification network에 spatial pooling layer는 object detection network에 있는 ROI pooling layer로 자연스럽게 바꼈다.
하지만 최근 sota image classification network(resnet, googlenet)는 fully convolution으로 design됐다.
유추에 의해, hidden layer가 없는 ROI별 subnetwork를 남기고 object detection architecture에 있는 공유된 convolutional subnetwork를 만드는 모든 convolutional layer를 사용하는 것이 자연스럽게 나타난다.
그러나 해결책은 network의 높은 classification 정확도와 일치하지 않는 낮은 detection 정확도를 가진다.
문제를 해결하기 위해, Faster R-CNN detector의 ROI pooling layer는 convolutional layer의 두 set 간에 부자연스럽게 추가되고 공유되지않는 ROI별 연산때문에 더 낮은 속도로 정확도가 증가하는 더 깊은 ROI별 subnetwork를 만든다.
앞에 언급된 부자연스러운 design은 image classification에 대한 translation invariance의 증가와 object detection에 대한 translation variance를 나타내는 dilemma가 원인이다.
한편으로는 image level classification task는 translation invariance를 사용한다.
그러므로 imagenet classification에 결과를 보면 가능한 translation invariant를 가지는 deep convolutional architecture가 선호된다.
반면에, object detection task는 translation variant를 가지는 localization representation이 필요하다.
ex) 후보 box에 있는 object의 translation은 후보 box가 object와 얼마나 많이 겹치는지를 나타내는 의미있는 response를 생성해야함.
image classification에 있는 deeper convolutional layer가 translation에 덜 세심하다는 가설을 세웠다.
dilemma를 다루기 위해, resnet 논문의 detection pipeline은 convolution에 ROI pooling layer를 추가한다.
region별 연산은 translation invariance를 안하고 ROI 이후 convoltional layer는 다른 region을 평가할 때, translation invariant를 더 이상 안 쓴다.
그러나 상당한 region별 layer의 수를 도입하기 때문에 training과 test 효율성이 떨어진다.


FCN에 translation variance를 포함하기 위해, FCN output처럼 특화된 convolutional layer를 사용함으로써 position sensitive score map의 set을 만들었다.
각각의 score map은 spatial position에 관한 position 정보를 encode한다.
FCN의 top에서 weight 없는 layer를 가지는 score map으로부터 정보를 shepherd하는 position sensitive ROI pooling layer를 추가한다.
전체 architecture는 end to end로 학습된다.
모든 학습가능한 layer는 convolutional이고 전체 image에 공유된다.
그러나, object detection에 대해 필요한 공간 정보가 필요한다.
backbone으로 101 layer resnet101을 사용해서 R-FCN은 PASCAL VOC 2007에서 83.6% mAP, 2012 set에서 82.0%를 달성한다.
그리고 resnet101을 사용해서 image당 Faster R-CNN + Resnet101보다 2.5~20배 더 빠른 170ms 속도로 test에서 달성했다.
이 실험으로 translation invariance와 variance 간에 dilemma를 다뤘고 resnet과 같은 fully convolutional image level classifier는 fully convolutional object detector로 효율적으로 바꼈다고 입증됐다.
Our approach
- overview

R-CNN 후에 나온 region proposal과 region classification으로 구성된 인기있는 two stage object detection 전략을 채택했다.
region proposal에 의존하지 않는 방법에도 불구하고 region에 기반된 system은 몇몇 benchmark에서 여전히 최고의 정확도를 가진다.
우리는 본질적으로 fully convolutional architecture인 RPN에 의해 후보 region을 추출한다.
RPN과 R-FCN 간에 feature를 공유한다.
ROI를 고려하면 R-FCN architecture는 object category와 background에 ROI를 분류하기 위해 design됐다.
R-FCN에서, 모든 학습가능한 weight layer는 convolutional하고 전체 image에서 연산된다.
마지막 convolutional layer는 각 category에 대한 $k^2$ position sensitive score의 bank를 생성한다.
그러므로 C개의 object category를 가지는 $k^2(C+1)$ channel output layer를 가진다.
$k^2$ score map의 bank는 상대적인 psoition을 묘사하는 k x k인 공간적인 grid에 해당한다.
ex) k x k =3 x 3으로 9 score map은 object category의 [top left, top center, top right, ... , bottom right]의 경우를 encode
R-FCN은 position sensitive Roi pooling layer로 끝난다.
이 layer는 마지막 convolutional layer의 output을 합치고 각 ROU에 대한 score를 생성한다.
우리의 position sensitive ROI layer는 selective pooling을 하고, 각각의 k x k bin은 k x k score map의 bank 중 한 score map에서만 response를 합친다.
end to end trainng으로 ROI layer는 전문화된 position sensitive score map을 학습하기 위해 마지막 convolutional layer를 사용한다.
- Backbone architecture
논문에서 R-FCN의 형태는 resnet101에 기반됐다.
resnet101은 global average pooling(gap)과 1000 class fc layer로 100개의 convolutional layer를 가진다.
average pooling layer와 fc layer를 없애고 feature map을 계산하기 위해 convolutional layer만 사용한다.
resnet 101에 있는 마지막 convolutional block은 2048 차원이고 차원을 줄이기 위해 무작위로 설정된 1024차원인 1x1 convolutional layer를 추가한다.
그 후 score map을 생성하기 위해 $k^2(C+1)$ channel convolutional layer를 적용한다.
- Position-sensitive score maps & Position-sensitive ROI pooling
각 ROI에 있는 position 정보를 encode하기 위해, regular grid에 있는 k x k bin으로 각 직사각형 ROI을 나눈다.
w x h 크기의 직사각형 ROI에 대해, bin은 $\frac{w}{k}$ x $\frac{h}{k}$ 크기다.
이 방법에서, 마지막 convolutional layer는 각 category에 대한 $k^2$ score map을 만들기 위해 만들었다.

(i, j)번쨰 bin에서, (i, j)번째 score map으로 pooling하는 position sensitive ROI pooling 연산을 정의
$r_c(i, j)$: c개의 category에 대한 (i, j) bin에서 pooling된 response
$z_{i, j, c}$: $k^2(C+1)$ score map 중에 한 개의 score map
$(x_0, y_0)$: ROI의 top lerft corner
n: bin에 있는 pixel의 수
$\theta$: network의 학습 가능한 모든 parameter
(i, j) bin 범위: $[i \frac{w}{k}]$ <= x < $[(i+1) \frac{w}{k}]$, $[j \frac{h}{k}]$ <= y < $[(j+1) \frac{h}{k}]$
Eqn(1)은 average pooling을 사용하지만 max pooling이 잘 된다.
$k^2$ postiion sensitive score는 ROI에 투표한다.
score를 평균내고, 각 ROI에 대한 (C+1)차원 vector를 만듦으로써 쉽게 투표한다.
그 후, category에서 softmax response를 계산한다.
그들은 inference동안 ROI를 순위 매기고 training동안 cross entropy loss를 평가한다.
$k^2(C+1)$차원 convolutional layer 외에, 우리는 bounding box regression에 대한 쌍둥이 $4k^2$차원 convolutional layer를 추가한다.
position sensitive ROI pooling은 각 ROI에 대한 $4k^2$차원의 vector를 생성하는 $4k^2$ map의 bank에 수행됐다.
그 후 voting을 평균으로 4차원 vector를 합쳤다.
4차원 vector는 t = $(t_x,t_y,t_w,t_h)$로 bounding box를 parameter화한다.
- Training
사전에 계산된 region proposal을 가지고 R-FCN architecture를 end to end로 학습하는 것은 쉽다.
각 ROI에 정의된 loss function은 cross entropy loss와 box regression loss의 합이다.
$L(s,t_{x,y,w,h}) = L_{cls}(s_{c*}) + \lambda [c^* > 0]L_{reg}(t,t^*)$
$c^*$: ROI의 ground truth label( $c^*$ = 0 = background)
$L_{cls}(s_{c*})$ = $-log(s_{c*})$: classification에 대한 cross entropy loss
$L_{reg}$: bounding box regression loss
$t^*$: ground truth box
$[c^* > 0]$: true면 1, 아니면 0
$\lambda$ = 1로 설정하고, IOU를 가지는 ROI는 적어도 0.5이상의 ground truth box로 겹쳐야 positive example이고 이하는 negative이다.
training하는 동안 OHEM을 채택하는 것이 R-FCN에 대해 쉽다.
ROI당 무시할만한 연산은 거의 cost없이 example mining이 가능하다.
forward pass에서 image당 N개의 proposal을 가정할 떄, 우리는 모든 N개의 proposal의 loss를 평가한다.
그 후, loss에 의해 모든 ROI를 sort하고 가장 높은 loss를 가지는 B ROI를 선택한다.
backpropagation은 선택된 example에 기반되서 수행된다.
ROI당 연산은 무시되기 때문에 forward time은 N에 의해 영향이 있지 않다.
반면에 OHEM fast R-CNN은 training time이 두배 더 걸린다.
weight decay: 0.0005
momentum: 0.9
learning rate: 0.001(20k mini batch) -> 0.0001(10k mini batch)
scale을 600 pixel로 resize된 image인 single scale training을 사용한다.
각 GPU는 1 image를 가지고 backprop에 대해 B = 128 ROI로 한다.
8 GPU로 model을 학습
RPN으로 feature를 공유하는 R-FCN을 가지기 위해, 우리는 RPN 학습과 R-FCN 학습 간에 교차로 4 단계의 alternating training을 채택한다.
- Inference
RPN과 R-FCN 간에 공유된 feature map은 연산됐다.
그 후 RPN은 R-FCN이 category별 score를 평가하고 bounding box를 regress하는 ROI를 제안한다.
inference동안 공정한 비교로 300개의 ROI를 평가한다.
결과는 0.3 IOU threshold를 사용하는 nms로부터 사후처리됐다.
- A trous and stride
fully convolutional architecture는 semantic segmentation에 대해 FCN을 사용해서 network 수정의 장점을 봤다.
score map resolution을 증가시키기 위해 resnet 101의 효과적인 stride를 32pixel에서 16pixel로 줄였다.
모든 layer 전에 conv4 단계는 바뀌지않았고 첫번째 conv5 block에 있는 stride=2 연산은 stride=1로 수정됐고, 감소된 stride에 대해 보상하기 위해 conv5 stage에서 있는 모든 convolutional filter는 hole algorithm으로 수정됐다.
공정한 비교를 위해 RPN은 conv4 단계 top에서 계산되어졌다.
그래서 RPN은 a trous trick에 의해 영향받지 않았다.
- Visualization



전문화된 map은 object의 특정 상대적인 위치에서 활성화되기 위해 기대된다.
만약 후보 box가 true object을 겹친다면, ROI에 있는 대부분 $k^2$ bin은 활성화되고 voting은 높은 점수를 만든다.
반면에, 맞지 않는 후보 box가 true object에 겹친다면, ROI에 있는 몇몇 $k^2$ bin이 활성화되지않고 voting 점수는 낮다.
Experiments
* Experiments on PASCAL VOC
20 object category를 가지는 PASCAL VOC에 실험을 한다.
VOC 2007 trainval과 VOC 2012 trainval(07+21)의 합집합에 model을 학습하고, VOC 2007 test set으로 평가된다.
object detection accuracy는 mAP에 의해 측정된다.
- Comparisons with Other Fully Convolutional Strategies
- naive faster R-CNN: 공유된 feature map을 계산하기 위해 Resnet 101에 있는 모든 convolutional layer를 사용하고 마지막 convolutional layer 뒤에 ROI pooling을 채택한다. 비싸지 않은 21개의 class fc layer는 각 ROI에 평가되고 a trous trick은 공정한 비교로 사용된다.
- class specific RPN: RPN은 2개의 class convolutional classifier layer가 21개의 convolutional classifier layer로 대체되는 것을 제외하고 학습되었다. 공정한 비교를 위해 class별 RPN에 대해 우리는 a trous trick으로 Resnet101의 conv5를 사용한다.
- R-FCN without position sensitivity: k = 1로 설정함으로써 R-FCN의 position sensitivity를 없앤다. 각 ROI 안에 global pooling과 동등하다
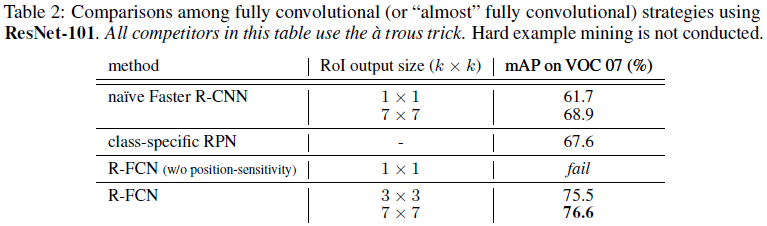
- Comparisions with Faster R-CNN Using Resnet 101



- On the Impact of Depth

- On the impact of region proposals

Experiments on MS COCO





Conclusion and future work
Region에 기반된 fully convolutional network 제시
우리의 system은 fully convolutional로 design된 sota image classification backbone(resnet) 채택
이 방법은 Faster R-CNN과 비교해서 비슷한 정확도로 보이지만, training과 inference 둘 다 훨씬 빠르다.
간단하게 논문에 제시된 R-FCN system을 유지한다.
object detection에 대해 region에 기반된 방법의 확장뿐만 아니라 semantic segmentation에 대해 발전된 FCN의 직교 확장 시리즈이다.
'computer vision > object detection' 카테고리의 다른 글
| YOLOv3: An Incremental Improvement (0) | 2024.04.03 |
|---|---|
| Focal Loss for Dense Object Detection (0) | 2024.03.12 |
| Training Region-based Object Detectors with Online Hard Example Mining (0) | 2024.02.23 |
| Feature Pyramid Networks for Object Detection (0) | 2024.02.19 |
| SSD: Single Shot MultiBox Detector (1) | 2024.02.08 |