Abstract
Transformer 구조가 nlp task에 대해 근본인 동안에 cv에서 적용은 제한되었다.
vision에서 attention은 convolutional network과 함께 적용되거나 전체 구조를 유지하는 동안 convolutional network의 일부 구성 요소를 대체하는 것 중 하나이다.
CNN에서 의존이 필수적이지 않다는 것을 나타내고 순수 transformer는 image classification task에서 아주 좋은 성능을 보이는 image patch의 sequence를 적용했다.
대량의 데이터에 대해 pretrain하고 여러 개의 중간 규모 또는 소규모 image recognition benchmark로 바꿨을 때, Vision Transformer(VIT)는 학습하기 위해 더 적은 연산량을 필요한 반면에 sota convolutional network와 비교된 훌륭한 결과를 얻었다.
Introduction
특히, Self attention에 기반된 구조인 Transformer는 nlp에서 model의 선택이 됐다.
우세한 방법은 많은 text corpus에 pretrain하는 것이고 그 다음 더 작은 task별 dataset에서 finetuning하는 것이다.
Transformer의 연산 효율성과 확장성 덕분에, 전례없는 크기(over 100B parameter)의 model로 학습하는 것이 가능해졌다.
그러나 cv에서는 convolutional 구조가 우세하다.
많은 work는 self attention을 가진 구조같은 CNN과 결합을 시도한다.
이론적으로는 효율적인 반면에 후속 model은 attention을 사용하기 때문에 최신 하드웨어에 효과적이지 않아서 여전히 고전적인 Resnet이 sota이다.
NLP에 Transformer에 영감을 받아서 image를 patch로 나누고 Transformer에서 input으로 patch의 선형 embedding의 sequence를 줘서 실험한다.
Image patch는 NLP에서 token처럼 같은 방법으로 했다.
강력한 규제 없이 imagenet과 같은 중간 규모 dataset으로 학습할 때 model은 Resnet의 비슷한 크기로 적당한 정확도를 냈다.
그러나 model이 더 큰 dataset으로 학습된다면 상황이 달라진다.
VIT는 충분한 크기로 pretrain되고 더 적은 datapoint로 task를 바꿨을 때, 훌륭한 결과를 얻었다.
Method
* Vision Transformer(VIT)

기존 Transformer는 token embedding의 1D sequence를 input으로써 받는다.
2D image를 다루기 위해서, flatten된 2D patch의 sequence로 image를 reshape한다.
(H,W): 원래 image의 해상도
C: channel의 수
(P, P): 각 image patch의 해상도
N = HW/P^2: 결과 patch의 수
Transformer는 모든 layer를 통해서 constant latent vector size D를 사용한다.
그래서 patch를 flatten하고 학습가능한 선형 투영으로 D 차원을 map한다.
projection의 output을 patch embedding이라고 한다.
Transfomer encoder의 output(z^0_L)에서 state가 image representation인 y에서 제공하는 embedded patch(z^0_0 = X_class)의 sequence에 학습가능한 embedding을 앞에 추가한다.
pretrain과 finetuning을 둘 다 하는 동안에, classification head는 z^0_L 뒤에 붙인다.
classification head는 pretraining에서 one hidden layer를 가진 MLP와 fine tuning에서 single linear layer에 의해 구현된다.
position embedding은 position 정보를 얻기 위해서 patch embedding을 더했다.
더 발전된 2D aware position embedding을 사용하는 것으로부터 상당한 성능 향상을 보지 못했기 때문에 학습가능한 1D position embedding을 사용한다.
embedding vector의 결과 sequence는 encoder에 input으로 사용된다.
Transformer encoder는 multiheaded self attention과 MLP block의 교차 layer로 구성된다.
Laynorm(LN)은 모든 block 전에 적용되고 모든 block 후에 residual connection한다.

- Inductive bias
ViT는 CNN보다 image별 inductive bias가 훨씬 낮다.
CNN에서 2차원 이웃 구조인 locality와 translation equivariance는 전체 model 내내 각 layer에 미리 계산된다.
ViT에서는 self attention layer가 global인 반면에 MLP layer에만 local이고 translationally equivariant이다.
2차원 이웃 구조는 model 시작할 때 image를 patch로 자르고 해상도가 다른 image의 position embedding을 조정할 때 fine tuning 할 수 있습니다.
초기화에서 position embedding이 처음부터 학습해야되는 patch 간에 patch의 2D postion과 모든 spatial 관계에 대한 정보가 없다.
- Hybrid Architecture
raw image patch의 대안으로, input sequence는 CNN의 feature map으로부터 형성되었다.
hybrid model에서 patch embedding projection E는 CNN feature map으로부터 추출된 patch에 적용됐다.
특별한 경우일 때, patch는 input sequence가 feature map의 공간적 차원을 flatten하고 Transformer 차원을 투영시킴으로써 얻어지는 spatial size 1x1을 가진다.
# classification input embedding과 postion embedding은 위에 묘사된 것을 더했다.
* Fine Tuning and higher resolution
큰 dataset으로 ViT를 pretrain하고 downsreakm task로 fine tuning한다.
그래서 pretrain된 prediction head를 없애고 0으로 초기화된 D x K인 feedforward layer를 추가한다.
K = downstream class의 수
고해상도 image를 줄 때, 더 큰 효과적인 sequence 길이를 사용해서 같은 size의 patch를 유지한다.
ViT는 임의의 sequence length를 다룰 수 있다.
그러나 pretrain된 position embedding은 더 이상 의미가 없어서 원래 image에 있는 location을 따라서 pretrain된 postion embedding의 2D interpolation을 한다.
해상도 조절과 patch 추출은 image의 2D 구조에 대한 inductive bias가 ViT에 더해지는 중요한 것이다.
Experiments
Resnet, Vit, hybrid의 representation learning을 평가한다.
각 model의 data 필요조건을 이해하기 위해서, 다양한 크기의 dataset으로 pretrain되고 많은 benchmark task를 평가한다.
pretrain하는 model의 연산 cost를 고려할 때, ViT는 더 낮은 cost로 pretrain되는 많은 recognition benchmark에서 sota를 얻는 좋은 성능을 보인다.
마지막으로, self supervision을 사용한 작은 실험을 했고 self supervised ViT가 미래에 가능성을 보인다.



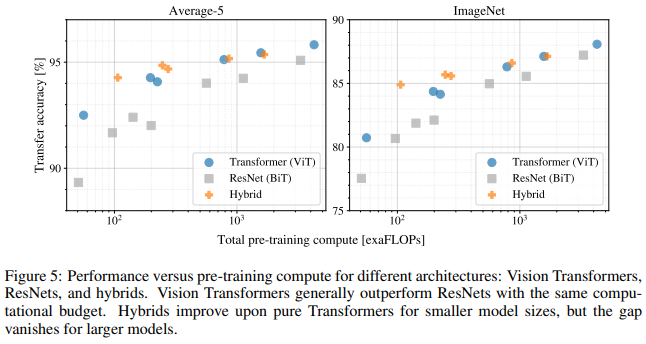


Conclusion
우리는 image recognition에서 Transformer의 적용을 했다.
computer vision에서 self attention을 사용하는 이전 work와 달리, 초기 patch extraction를 제외하고 구조에서 image별 inductive bias를 도입하지 않았다.
대신에, patch의 sequence로 image를 설명하고 NLP에 사용된 Transformer encoder에 의해 처리한다.
large dataset에 pretrain할 때, 간단하면서도 확장가능한 전략은 잘 먹힌다.
따라서 ViT는 많은 pretrain하는데 상대적으로 싼 image classification dataset에서 sota이고 능가한다.
- 문제점
1. detection과 segmentation같은 computer vision task에 ViT 적용하는 것(but 적용 가능성 보임)
2. self supervised pretraining method를 계속 하는 것(처음에는 잘 되다가 large scale supervised pretrain한테 참패)
ViT를 확장하는 것은 성능 향상을 나타낼 것으로 보임
'transformer' 카테고리의 다른 글
| Training data-efficient image transformers& distillation through attention (1) | 2024.02.01 |
|---|---|
| Attention Is All You Need (0) | 2024.01.17 |